Manually designing reward functions is often infeasible, and standard inverse reinforcement learning methods incur high sample complexity by requiring nested RL solves. We propose meta learning a soft Q-function prior across related tasks to enable few-shot imitation without an explicit reward network nor inner solves. Specifically, during meta training, we update Q-parameters for a specific task on a small set of demonstrations and optimize the initialization to minimize the inverse soft Bellman residual on held-out data, effectively learning transferable Q-function features. At test time, a single gradient step on a few demonstrations yields both an approximate optimal policy and its underlying reward, eliminating costly inner loop RL. This approach offers significant advantages in sample efficiency, computational simplicity, and stability compared to prior meta IRL methods. We demonstrate the efficacy of this method through a comprehensive experimental pipeline that includes procedurally generated pixel based tasks.

Project
Term Project Presentation and Poster Session
- Date: 2024/06/11 (Wednesday)
- Time: 3:30PM- 5:30PM
- Location: Room 106 and 1st Floor, Building 301
Schedule
- 3:20 PM ~ 3:40 PM: Session 1 Presentation (Room 106, Building 301)
- 3:40 PM ~ 4:10 PM: Session 1 Poster Session (1st Floor, Building 301)
- 4:10 PM ~ 4:30 PM: Session 2 Presentation (Room 106, Building 301)
- 4:30 PM ~ 5:00 PM: Session 2 Poster Session (1st Floor, Building 301)
Algorithmic Foundations of RL
RL for Robotics & AI Systems
- Force-Aware Deformable Object Manipulation with Diffusion policy (강승훈) - Best Poster Awards!
1. Algorithmic Foundations of RL
Meta Learning Q-Function Priors for Efficient Few-Shot Imitation (Barro Alessandro)

COMPASS: A Comparative Framework and Meta-Algorithm for Robust Imitation Learning from Imperfect Demonstrations (Hernandez Tavera Faiber Alonso)

Handling imperfect demonstrations is a critical challenge in imitation learning, yet systematic evaluation frameworks for algorithm robustness remain underdeveloped. A comprehensive comparative analysis framework named COMPASS is presented, which systematically evaluates imitation learning algorithms across four distinct imperfection types: trajectory noise, task failures, strategic inconsistency, and embodiment mismatch. COMPASS enables principled algorithm selection based on the specific characteristics of imperfect demonstration data. Five state-of-the-art algorithms are evaluated: Behavioral Cloning, IQ-Learn, DemoDICE, Example-Based Policy Search, and the proposed Adaptive Demonstration Filtering meta-algorithm (ADF), across varying imperfection severities. The conducted experiments reveal that DemoDICE demonstrates superior overall robustness (50% success rate), while EBPS exhibits counterintuitive negative degradation, actually improving performance on certain corrupted datasets. Through statistical analysis of 300 controlled experiments, distinct robustness patterns are identified: noise impacts differ significantly from failure-based corruptions, with degradation ranging from 8% to 150% depending on algorithm-imperfection pairing. The findings provide the first systematic guidelines for future practitioners to select appropriate imitation learning algorithms based on anticipated demonstration quality, addressing a critical gap in robust robot learning deployment.
Evaluating Modern Reinforcement Learning Methods for Reservoir Computing in Robotic Control (Tykesson Tage)

Reservoir Computing (RC) is a framework for temporal processing that uses a fixed, randomly connected recurrent network—called a reservoir—to project sequential inputs into a high-dimensional dynamic space. With untrained internal weights, only a simple readout layer is optimized, enabling
fast and stable learning. This architecture is well-suited for tasks with time-dependent dynamics, such as robotic control or chaotic systems. Koulaeizadeh and Oztop previously introduced Dynamic Adaptive Reservoir Computing (DARC), which integrates reinforcement learning with an Echo State Network (ESN) by modulating a task-specific context vector. In this project, we reproduce the original DARC architecture using Proximal Policy Optimization (PPO) and extend it by evaluating alternative RL algorithms, including Soft Actor-Critic (SAC), Trust Region Policy Optimization (TRPO), and Deep Deterministic Policy Gradient (DDPG). Experiments are conducted on the Gymnasium Reacher environment, a continuous control task where the agent must actuate a two-joint arm to reach variable target positions. To evaluate generalization, the reservoir is trained and tested on distinct sets of target positions. Each method is assessed based on final reaching accuracy and sample efficiency. The results show meaningful differences in how the tested
reinforcement learning algorithms interact with the reservoir-based control architecture highlighting the importance of algorithm selection when combining reservoir computing with policy learning and support the broader viability of this hybrid approach for continuous control tasks.
fast and stable learning. This architecture is well-suited for tasks with time-dependent dynamics, such as robotic control or chaotic systems. Koulaeizadeh and Oztop previously introduced Dynamic Adaptive Reservoir Computing (DARC), which integrates reinforcement learning with an Echo State Network (ESN) by modulating a task-specific context vector. In this project, we reproduce the original DARC architecture using Proximal Policy Optimization (PPO) and extend it by evaluating alternative RL algorithms, including Soft Actor-Critic (SAC), Trust Region Policy Optimization (TRPO), and Deep Deterministic Policy Gradient (DDPG). Experiments are conducted on the Gymnasium Reacher environment, a continuous control task where the agent must actuate a two-joint arm to reach variable target positions. To evaluate generalization, the reservoir is trained and tested on distinct sets of target positions. Each method is assessed based on final reaching accuracy and sample efficiency. The results show meaningful differences in how the tested
reinforcement learning algorithms interact with the reservoir-based control architecture highlighting the importance of algorithm selection when combining reservoir computing with policy learning and support the broader viability of this hybrid approach for continuous control tasks.
I-Stream : Pixel-based Deep Reinforcement Learning Without Batch Updates and Replay Buffers (노승원)
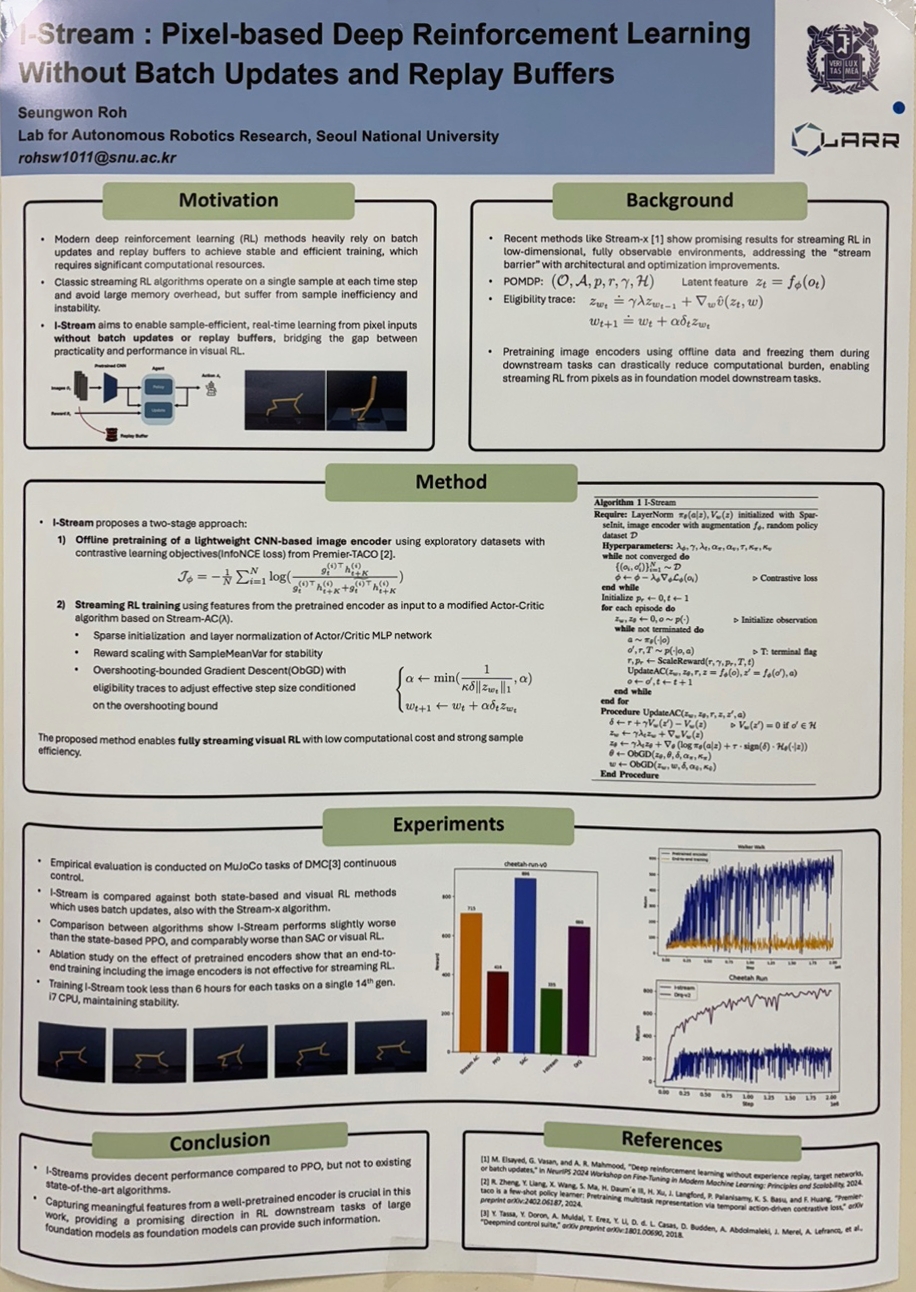
We introduce I-Stream, a pixel-based deep reinforcement learning (RL) framework that operates in a fully streaming setting—without replay buffers, batch updates, or target networks. While batch RL benefits from computational efficiency and sample reuse via replay buffers, it remains impractical for latency-sensitive or resource-constrained environments. I-Stream addresses this challenge by decoupling image representation learning from policy learning. Specifically, we employ a pretrained convolutional encoder to extract compact latent features from high-dimensional image inputs, which are then fed into a adapted streaming version of the actor-critic algorithm, Stream-AC(λ). This design enables stable and sample-efficient policy learning using a single sample per time step. Extensive comparisons against both batch and streaming visual RL baselines validate the effectiveness of I-Stream, showing promising performance while significantly reducing computational overhead. Our work offers a viable solution for real-time visual RL in constrained scenarios.
Can Zero-shot RL enable test time safety? (민준규)

Zero-shot reinforcement learning (ZSRL) aims to produce policies that generalize to novel reward functions without task-specific training, offering particular advantages in offline RL. Existing approaches such as Forward-Backward (FB) representations enable reward generalization by decoupling dynamics and rewards via learning successor representations. However, current ZSRL methods lack safety guarantees at test time, which are critical in deployment. We propose a simple method to enable zero-shot safe RL that integrates safety constraints into the FB representation. This allows test-time policy adaptation to both reward and cost functions without additional training. The method achieves competitive performance against prior offline safe RL baselines
BiCQL-ML: A Bi-Level Conservative Q-Learning Framework for Maximum Likelihood Inverse Reinforcement Learning (박준성)

Offline inverse reinforcement learning (IRL) seeks to recover the underlying reward function that explains expert behavior using only static demonstration data, without access to online environment interaction. We introduce a novel policy-free offline IRL algorithm,BiCQL-ML, that optimizes a reward function and a conservative Q-function in a bi-level, entirely avoiding explicit policy learning. Our method bi-optimizes between (i) learning a conservative Q-function via Conservative Q-Learning (CQL) under the current reward, and (ii) updating the reward function parameters to maximize the expected Q-values of expert actions while suppressing over-generalization to out-of-distribution (OOD) actions. This process can be interpreted as a maximum likelihood estimation (MLE) framework under soft value matching. We provide theoretical guarantees that the algorithm converges to a reward function under which the expert policy is (soft-)optimal. Our experimental results demonstrate that the proposed method successfully offline IRL, outperforming IRL baselines(BC,DAC,ValueDice) on a diverse collection of robotics training tasks in MuJoCo simulator, as well as datasets in D4RL benchmarkin standard D4RL benchmarks These results demonstrate the effectiveness and robustness of IRL framework in purely offline settings.
A Recency-Aware Prioritization Strategy for Experience Replay in Deep Q-Networks (서바다)

We present a recency-aware prioritization strategy for experience replay in Deep Q-Networks, addressing limitations of conventional PER which relies solely on TD error. By incorporating temporal recency into the sampling probability, our method selectively emphasizes both informative and timely transitions. This design aims to improve learning efficiency, particularly in sparse-reward environments like Atari Breakout. Implemented within the Rainbow DQN framework, our approach sets the stage for controlled evaluation of how adaptive prioritization can enhance sample utility without increasing computational complexity.
Escaping Local Minima in Optimal Transport Based Curriculum RL via Certified Smoothing (신윤호)

Curriculum reinforcement learning (CRL) enhances policy learning by sequencing tasks from easy to hard. While diverse methods emerge, interpolation-based methods like CURROT, which leverage optimal transport (OT) with performance constraints, have shown strong performance for specific target distributions. However, the process may encounter local minima due to the non-convexity caused by the performance constraints. We propose a novel approach using certified Gaussian smoothing to escape these minima, applying Gaussian noise to smooth the Wasserstein distance objective and performance constraints in CURROT’s framework. By convolving the optimization landscape, our method ensures robust convergence to global optima, backed by theoretical guarantees. This paper further introduces reactive constraint updates driven by GP uncertainty, enabling adaptive task sequencing. Empirical evaluations on benchmark tasks are conducted to demonstrate our approach’s performance. This work advances OT-based CRL by combining certified optimization with practical robustness, offering a scalable solution for complex RL environments.
QMPC Approach for Improving Stability in Model-Based Reinforcement Learning (윤형로)

There is a growing interest in developing efficient data-driven control methods applicable to digitized industrial systems. Model-free reinforcement learning (RL) has shown promise in learning optimal control policies directly from process data. However, model-free RL suffers from high cost variance and often requires an impractically large amount of data. Inspired by the high data efficiency and stable performance of model-based approaches, this paper proposes QMPC, a model predictive control framework that integrates MPC with Q-learning. QMPC improves learning stability while ensuring constraint satisfaction. In case studies with nonlinear benchmark systems including the Van de Vusse CSTR and a hybrid power-split system, QMPC demonstrates faster learning and lower cost variance compared to PPO.
Coordinated Multi-Policy Reinforcement Learning with Decomposed Objectives and Shared Experience (임민택)

Conventional reinforcement learning (RL) typically relies on a single policy optimized for a unified reward, which often fails to scale in complex tasks involving multiple, conflicting objectives. In such settings, a single policy tends to collapse into behavior that averages across competing goals, resulting in suboptimal or unstable performance. To address this limitation, we propose a unified framework that learns multiple specialized policies through decomposed reward optimization and shared experience. Each policy is guided by a personalized reward function, formulated as a learnable linear combination of task-relevant reward features, enabling interpretable and distinct behavioral strategies. To maintain diversity, we incorporate a KL-based regularization that discourages behavioral overlap, and a shared replay buffer that supports selective imitation of high-return trajectories across policies, allowing for mutual bootstrapping without convergence to identical solutions. At inference time, a gating network dynamically blends policies based on the current state or a goal-conditioned reward vector, enabling adaptive, context-sensitive control. Experiments on MuJoCo continuous control tasks show that our method improves behavioral diversity, sample efficiency, and generalization compared to single-policy and ablation baselines.
Federated Parameter Sharing In Multi-agent Reinforcement Learning (임진우)

A recent successful advance in multi-agent reinforcement learning is centralized learning with decentralized execution (CTDE). One tradition frequently performed in CTDE is parameter sharing, which employs the neural network with the same parameter for all or selected agents. However, decentralization can be a requirement for certain tasks and communication between agents can be costly, which makes it hard to perform parameter sharing. In order to both share the information between agents and reduce the amount of communication, we propose federated parameter sharing. The implicit bias of federated learning enables a moderate personalization of each agent and generalization of the neural network. In cases where agents are homogeneous, federated parameter sharing can show better performance even than full parameter sharing. In cases where agents are heterogeneous, federated parameter sharing sometimes shows worse performance than independent training.
View-Imagination: Enhancing Visuomotor Control with Adaptive View Synthesis (이도혁)
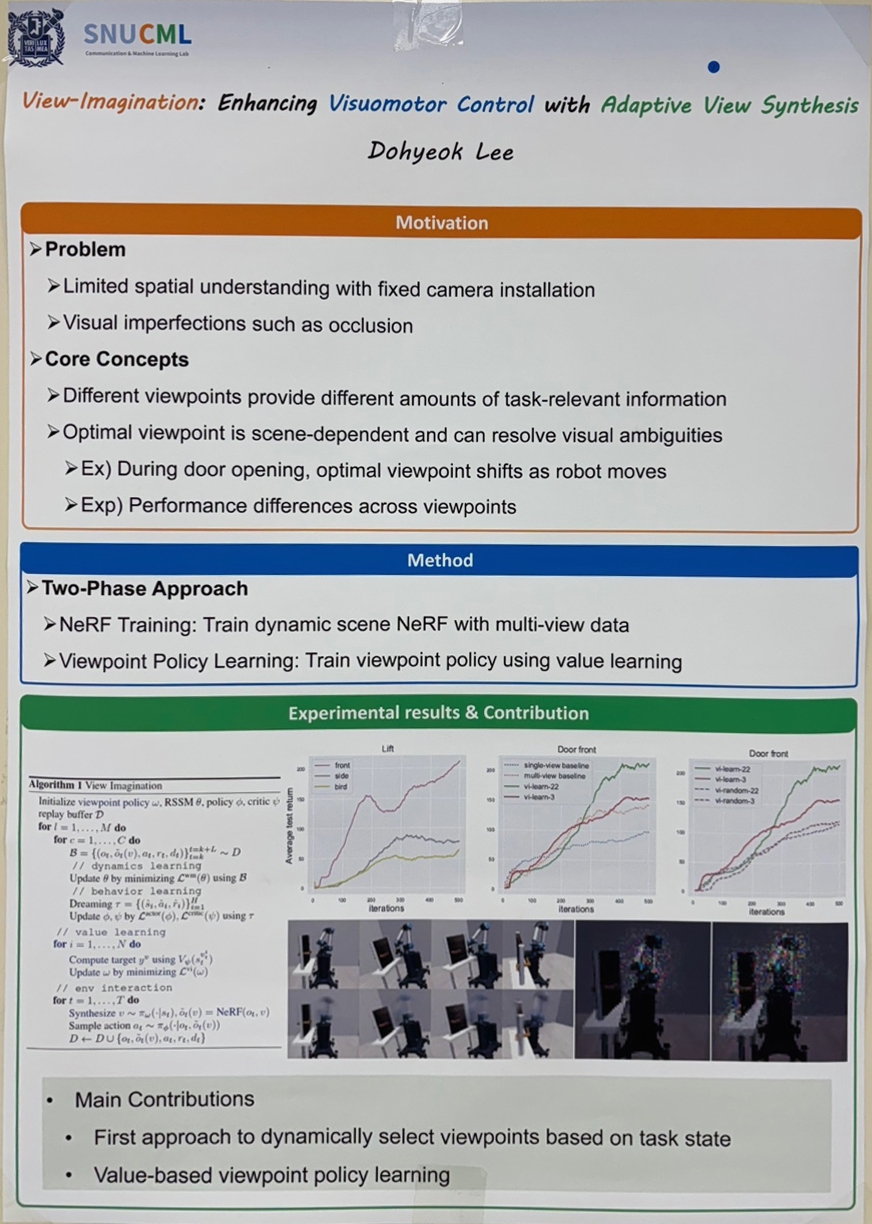
In robotic manipulation tasks, visuomotor control suffers from limited spatial understanding problems with limited camera installation and visual imperfections, such as occlusion. In this paper, we propose view-imagination, a novel framework with incorporating viewpoint policy. We train a dynamic scene NeRF and a learnable viewpoint policy, enabling the robot to generate a maximum value viewpoint to improve affordance. In experiments, we demonstrate that view-imagination outperforms across various training configurations.
Online Domain Adaptation for Cooperative Space Debris Manipulation (강승빈)

Reinforcement Learning (RL) has demonstrated remarkable performance in robotic manipulation tasks when trained in simulation environments. However, transferring these policies to real-world scenarios often results in significant performance degradation due to domain gaps, such as parametric uncertainty. In this paper, we propose a new framework that combines RL with Model Reference Adaptive Control (MRAC) to enable robust online domain adaptation. Our approach focuses on the cooperative manipulation of space debris using multiple robots rigidly attached to the debris, with their positions, orientations, and physical properties initially unknown. The proposed framework adapts the learned policy in real time to manipulate the debris to desired configuration. Experimental results demonstrate that our method significantly improves policy robustness and generalizability across domains, paving the way for effective and reliable space debris removal.
Fault-Tolerant Control of VTOL UAVs via Reinforcement Learning and Constraint-Aware Allocation (박종민)

Fixed-wing vertical takeoff and landing (VTOL) unmanned aerial vehicles (UAVs) are vulnerable to rotor failures due to their actuator layout and exposure to external disturbances. To address this vulnerability, this study proposes a reinforcement learning-based approach for fault-tolerant control of fixed-wing VTOL UAVs operating under rotor failure conditions. Traditional fault-tolerant control approaches often employ fault-dependent mode switching control approaches - conventional nonlinear controllers for less severe failure cases and reduced attitude controller for more critical failures. In comparison to the traditional approaches, a unified reinforcement learning-based approach proposed in this study directly generates generalized forces and moments based on the dynamic state of the aircraft. These virtual control inputs are then mapped to actuator commands using a constraint-aware control allocation mechanism, ensuring feasibility even under faulty actuator conditions. The policy is trained offline with randomized failure scenarios and initial conditions. By doing so, the controller is enabled to generalize across a wide range of fault conditions without manual mode switching or reconfiguration. The efficacy of the proposed approach is evaluated in simulation environments, and the RL-based controller shows stable control integrity across various fault scenarios and exhibits favorable convergence behavior in state regulation. This method adopts a safe reinforcement learning approach by ensuring that all learned control commands are translated physically feasible actuator inputs through integration of the allocation framework, demonstrating its potential as a scalable and effective alternative to conventional fault-tolerant control strategies.
Dynamics-Aligned Flow Matching Policy for Robot Learning (이정민)

Behavior cloning methods for robot learning suffer from poor generalization due to limited data support beyond expert demonstrations.
While recent approaches leverage video prediction models to implicitly capture dynamics, they lack explicit action conditioning, leading to averaged predictions over actions that obscure critical dynamics information. We propose a Dynamics-Aligned Flow Matching Policy that integrates dynamics prediction into policy learning through iterative flow generation. Our method introduces a novel architecture in which the policy and dynamics models share intermediate generation samples during training, enabling self-correction and improved generalization. We provide both theoretical analysis and empirical evidence demonstrating that our method achieves superior approximation performance compared to existing behavior cloning baselines.
While recent approaches leverage video prediction models to implicitly capture dynamics, they lack explicit action conditioning, leading to averaged predictions over actions that obscure critical dynamics information. We propose a Dynamics-Aligned Flow Matching Policy that integrates dynamics prediction into policy learning through iterative flow generation. Our method introduces a novel architecture in which the policy and dynamics models share intermediate generation samples during training, enabling self-correction and improved generalization. We provide both theoretical analysis and empirical evidence demonstrating that our method achieves superior approximation performance compared to existing behavior cloning baselines.
Behavior Cloning for Construction Tasks via Generalized Cylinder Representations (신승민)
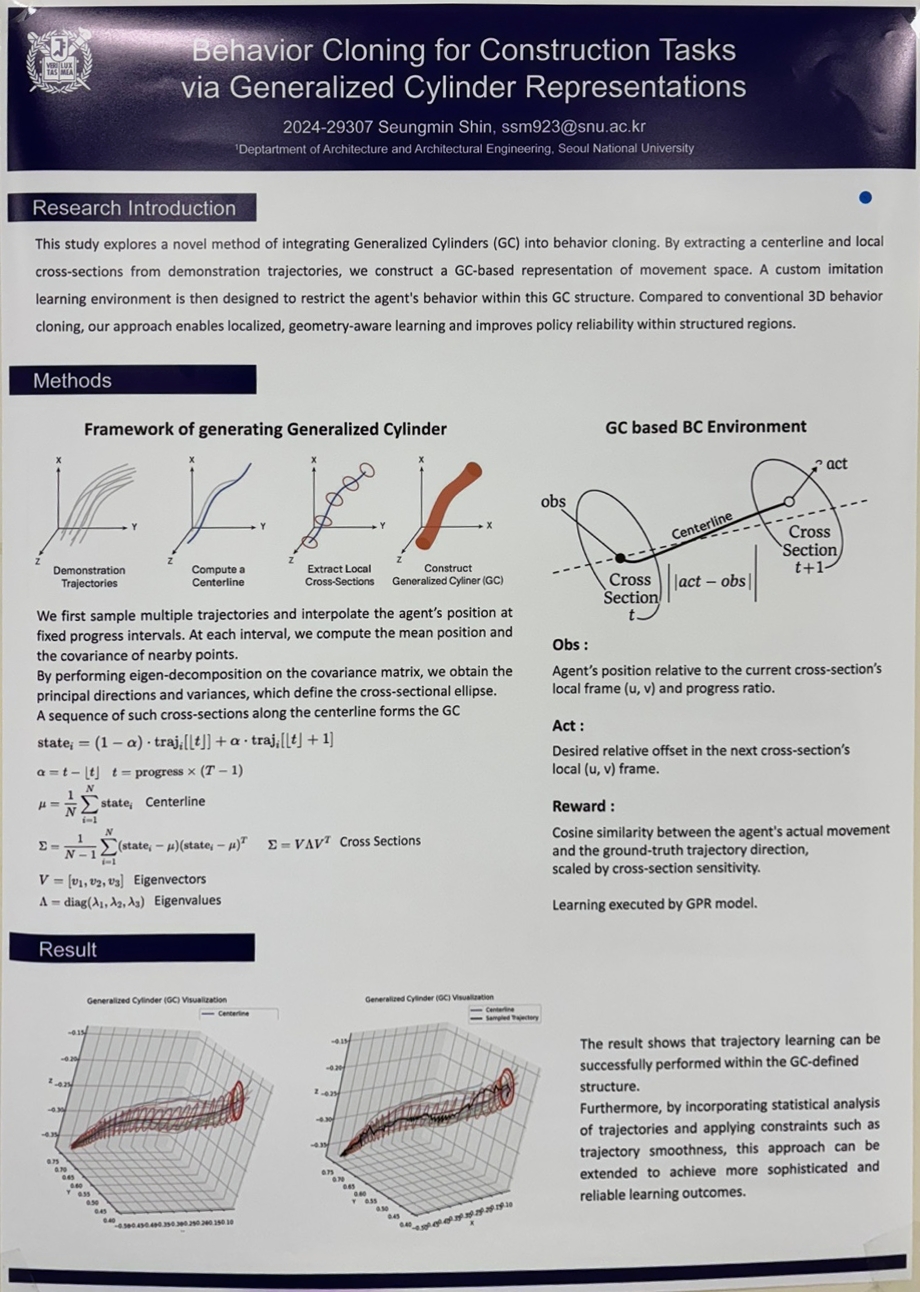
Behavior cloning has been widely used for imitation learning in simple robot tasks, but its effectiveness diminishes when applied to complex 3D tasks such as those in construction. Generalized Cylinders (GCs) have been proposed as a compact and structured representation of 3D robot trajectories, capturing both the mean path and the spatial variance of motions. In this work, I propose a novel behavior cloning framework that leverages the GC structure by representing each step of a trajectory with its corresponding cross-section. This GC-based representation enables more structured learning of spatial features, allowing the robot to more effectively imitate complex 3D trajectories in construction scenarios.
Hybrid Imitation and Reinforcement Learning for Autonomous Navigation in Realistic Driving Simulations (조성환)

Autonomous navigation in urban environments presents unique challenges such as dynamic obstacles, traffic rules, and partial observability. While imitation learning (IL) enables fast policy acquisition from expert trajectories, it struggles to generalize beyond known situations. Reinforcement learning (RL), on the other hand, is capable of exploration but often suffers from sample inefficiency and instability in safety-critical domains. In this project, we propose a hybrid learning framework that combines IL and RL to train robust navigation policies for autonomous driving. We use the Waymax simulator—built on real-world trajectory data from the Waymo Open Dataset—to evaluate our approach in complex driving scenarios including intersection navigation, lane-following, and obstacle avoidance. Our method first pretrains a policy via behavioral cloning and then fine-tunes it using Proximal Policy Optimization (PPO) to improve adaptability and performance under sparse rewards. We benchmark our hybrid approach against IL-only, RL-only, and DAgger baselines using success rate, rule violation rate, and robustness to dynamic changes. The proposed framework aims to bridge the gap between fast learning and safe, adaptable decision-making for realistic autonomous navigation.
2. RL for Robotics & AI Systems
Reinforcement Learning For Automatic Parking System (신종현)

In an automatic parking system, it is essential to consider multiple objectives such as safety, parking efficiency, and the quality of the final parking outcome. Most current approaches rely on data from skilled human drivers or heuristic prior knowledge. However, obtaining a substantial amount of high-quality expert driving data is challenging, and depending solely on human knowledge does not guarantee optimal results in a multi-objective parking scenario. In this paper, we propose a model-free reinforcement learning approach that continuously accumulates experience from numerous parking attempts. The agent learns the optimal steering and acceleration actions for different states by iteratively generating training data and updating the network parameters in each episode. With the proposed method, we significantly reduce reliance on human expertise and rapidly learn an autonomous parking strategy. The learned strategy ensures multi-objective optimization of safety, parking efficiency, and final parking accuracy. We establish a simulation environment approximating real-world conditions, define the vehicle's actions and observations, design a reward function that captures various objectives, determine episode termination conditions, and train the agent through repeated interactions with the environment. Experimental results demonstrate that the proposed flexible system can adaptively perform well under a variety of parking conditions.
Force-Aware Deformable Object Manipulation with Diffusion policy (강승훈)
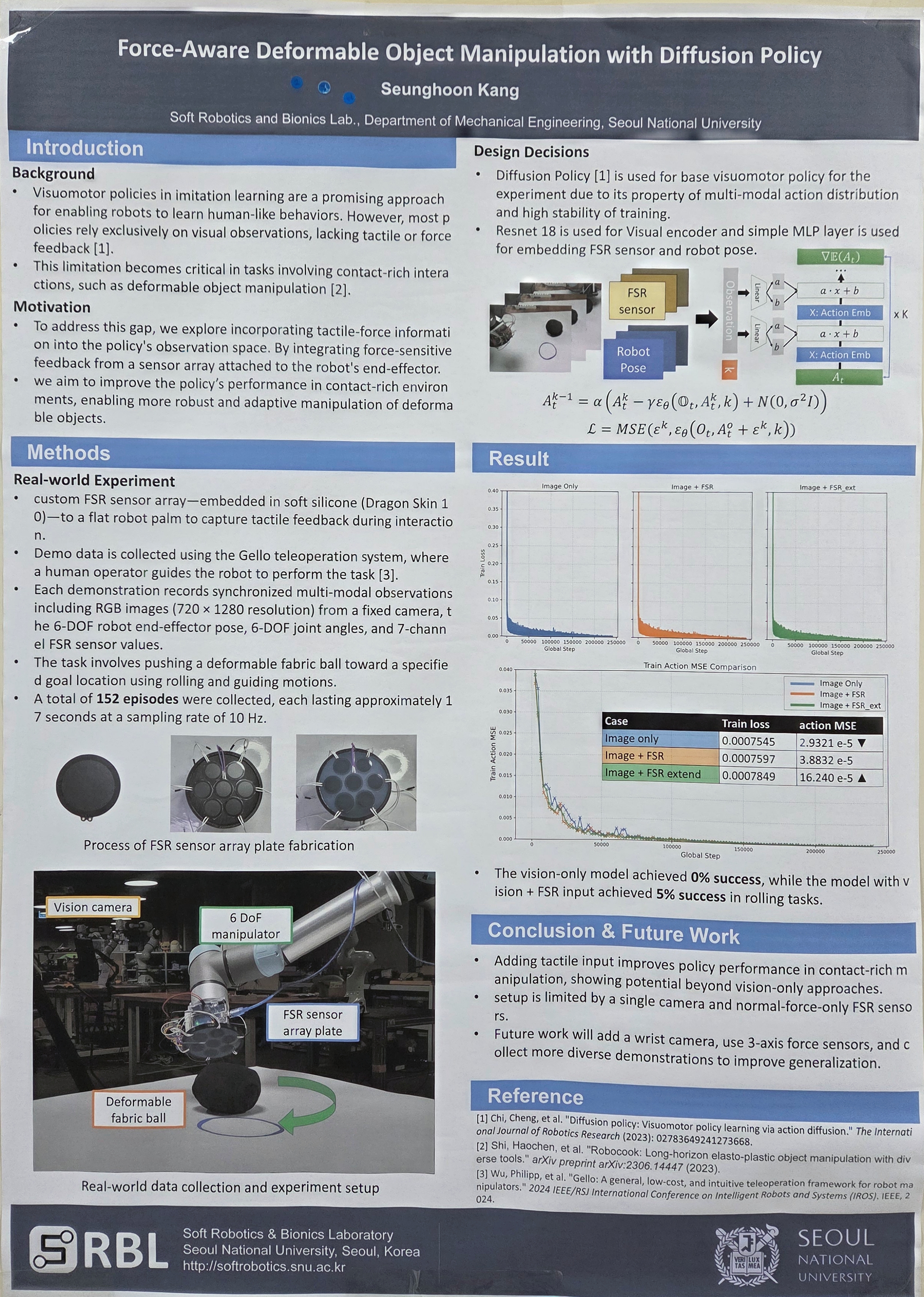
Humans naturally rely on both vision and touch to skillfully manipulate deformable objects. However, most visuomotor policies for robots are trained using only visual observations, limiting their ability to reason about contact-rich interactions. In this work, we propose a force-aware policy for deformable object manipulation by augmenting a diffusion-based action predictor with tactile information. Our setup consists of a flat palm equipped with a force sensing resistor (FSR) array, mounted on a robotic manipulator. Tactile signals are converted into image-like representations and encoded into the observation space alongside visual input, enabling multi-modal conditioning within an end-to-end diffusion policy framework. We train the policy on teleoperated demonstrations of rolling and guiding a soft clay object toward a target location. While still under evaluation, we hypothesize that incorporating tactile input may enhance the robustness and effectiveness of manipulation policies compared to vision-only baselines. This work explores the integration of touch sensing into diffusion-based control and aims to contribute toward more capable and generalizable deformable object manipulation in real-world settings such as food preparation, soft manufacturing, and medical robotics.
Reinforcement Learning-based Prior Map Localization Using Odometry Uncertainty (서형석)

With the advancement of robotic technologies, the importance of localization—the ability of a robot to navigate stably and accurately determine its position in various environments—has become increasingly significant in applications such as autonomous driving, exploration, and delivery. Map-based localization techniques, which estimate the current position using a pre-constructed prior map, have continuously improved with the development of SLAM and various vision- and LiDAR-based technologies. However, in real-world environments, due to the physical limitations of sensors and environmental complexity, issues such as false loop closures or false detections can still lead to incorrect position estimations.
For example, vision-based sensors may misrecognize different locations as the same place in environments with poor texture, low illumination, or repetitive patterns. Similarly, LiDAR sensors can struggle to accurately estimate position in environments with simple or repetitive structures due to matching errors. As such, the quality of observational data collected by the robot and the resulting localization performance can vary significantly depending on the viewpoint.
Previous studies on Uncertainty-Aware Model Predictive Control (UA-MPC) have quantitatively modeled odometry uncertainty based on viewpoint and used this to control the rotation direction of a motorized LiDAR, thereby improving odometry performance.
This study proposes a reinforcement learning-based viewpoint selection method that actively improves localization performance by leveraging uncertainty information associated with different viewpoints. Specifically, when the robot can steer its sensor in a certain direction, it computes the localization uncertainty for that viewpoint and uses an uncertainty-aware reward function to train a policy. The policy is trained using the Proximal Policy Optimization (PPO) algorithm, enabling the robot to autonomously choose directions that enhance localization performance.
This study focuses on LiDAR-based localization scenarios, with simulations conducted in the MARSIM environment. Experimental results show that the proposed RL-based viewpoint selection method significantly improves localization success rates compared to conventional approaches, especially in environments with repetitive or symmetrical structures where false loop closures are common. This research demonstrates the potential of active perception to enhance localization performance and lays the groundwork for future real-world applications and extensions to multi-sensor fusion.
Reward Refinement for High-Precision Hand-Object Trajectory Imitation (오우진)

Obtaining dexterous robotic object manipulation is challenging due to the expensive robot cost and time-consuming process. There have been many trials to get human-like manipulation without using such teleoperation systems. Among recent works, ManipTrans showed astonishing performance of generating realistic manipulation trajectories from ground-truth hand-object trajectory. However, even though they showed surprising result, some trajectory deviates noticeably from the reference trajectory, which limits the trajectory transformation to robot hands. In this paper, we address this limitation by redesigning previous work’s reward function to near-perfect tracking of the ground-truth trajectories. Since imitation learning such as Behavior Cloning is not suitable due to the difference of configuration between human and robot hand, we retain a PPO-based reinforcement learning framework but augment its imitation-style rewards with additional terms that explicitly penalize final-step pose errors and encourage stepwise alignment in both position and orientation. Our enhanced reward captures end-effector and object pose with higher fidelity, incorporates terminal‐step penalties for hand/object misalignment, and balances velocity and force tracking to ensure smooth, physically plausible motions.
Domain-Aware Offline Policy Learning for Service Robots in Diverse Real-World Environments (이승현)

Deploying service robots across diverse real-world environments—such as hospitals, offices, and public institution—poses challenges due to differences in spatial layout, crowd patterns, and operational constraints. Policies trained in one setting often fail to generalize to others, and online retraining is impractical in many real-world deployments. This research proposes a domain-generalized policy learning framework that enables robust policy transfer using only offline data. This method augments the robot’s state representation with domain descriptors, including site type, presence of elevators or automatic doors, obstacle density, and crowd levels. Environmental uncertainty is modeled using a Partially Observable Markov Decision Process (POMDP). Domain-conditioned reward functions are estimated via Leveraged Gaussian Process Regression (LGPR), and the policy is optimized through Guided Policy Search (GPS) and further refined with Conservative Q-Learning (CQL). This research evaluates the framework using a multi-domain offline dataset of indoor service robot trajectories from AI-Hub. Additionally, domain shifts are simulated in OpenAI Gym environments by injecting domain parameters to test shared policy performance. Results show improved success rates and generalization to unseen domains. Our findings emphasize the importance of domain awareness and uncertainty modeling in effective offline policy transfer for service robotics.
Capturing a Multi-Modal Grasping Dataset with the Inspire and Allegro Hands (최민기)

We captured a grasping dataset using the Inspire and Allegro robotic hands. The dataset includes diverse modalities collected through a multi-camera setup and tactile sensors, providing both visual and tactile information during grasping. Using this dataset, we trained and evaluated various existing grasping methods, and conducted an in-depth analysis of their performance across different object types and sensing conditions.
Multi-Agent Reinforcement Learning for Multi-Object Tracking using Adaptive Proximal Policy Optimization (Hidayat Ignatio)

Multi-Object Tracking (MOT) is a fundamental task in computer vision that involves detecting and tracking multiple objects while preserving their identities across video frames. Recent work has explored the use of Deep Reinforcement Learning (DRL) to formulate MOT as a sequential decision-making problem, where an agent learns an optimal tracking policy by processing visual and state information. One such approach, Multi-Agent Reinforcement Learning for Multi-Object Tracking (MARLMOT), employs a decentralized framework in which each object is tracked by an independent agent updating a Bayesian filter. MARLMOT originally utilizes Trust Region Policy Optimization (TRPO) for policy training, a method that ensures stable updates through constrained optimization but incurs high computational costs due to its reliance on second-order gradients. In this work, we propose replacing TRPO with Proximal Policy Optimization (PPO), a first-order policy gradient method that approximates TRPO’s trust region via a clipped surrogate objective. This modification reduces computational overhead while maintaining training stability. Furthermore, we introduce an adaptive clipping mechanism to address limitations of standard PPO, where fixed clipping bounds can lead to inefficient learning when policy updates vary significantly across states. Our approach enhances learning efficiency and improves update stability.
Reinforcement-Guided Subtask Decomposition for Unified Vision-Language Learning (김남기)

Multimodal models integrating vision-language tasks — such as segmentation, object detection, and grounded captioning —frequently encounter task interference, where optimizing one task compromises another due to shared parameter conflicts. This interference hinders generalization, especially on out-of-distribution data. To address this, we propose a reinforcement learning framework that implicitly decomposes complex tasks into shared subtasks, such as object localization and attribute interpretation, using the GRPO algorithm. The model is trained end-to-end with a composite reward system that combines format rewards for correct output structure, planning rewards for appropriate subtask selection, and task-specific rewards evaluating the answer quality. This approach eliminates the need for explicit subtask labels or multi-stage supervision, reducing error propagation and negative information transfer across tasks. By learning to structure outputs through common subtasks, our method enables better knowledge transfer between related vision-language tasks while maintaining task-specific performance. Our framework applies to diverse applications, including referring segmentation, visual question answering, and caption generation, offering a principled approach to training more robust and generalizable multimodal systems.
Meta Personalized Preference Learning for Adaptive Alignment of Large Language Models (김민성)

Reinforcement Learning from Human Feedback (RLHF) aligns large language models (LLMs) to an average human preference, leaving minority or idiosyncratic user tastes underserved. To address this issue, we introduce Meta Personalized Preference Learning (MPPL), a meta-learning extension of RLHF that endows an LLM with the ability to rapidly specialize to a new user after only a handful of feedback comparisons.
Data Augmentation through Neural Feature Randomization for Embodied Instruction Following (김병휘)

The pursuit of intelligent robotic agents capable of following natural language instructions to perform everyday tasks in complex, visually rich environments is a central goal in embodied AI. While imitation learning has proven effective for training such agents, it remains vulnerable to visual distribution shifts between training and deployment. Existing solutions rely on handcrafted image-level augmentations, which often require extensive tuning and may not generalize well. In this work, we introduce Neural Feature Randomization (NFR), a novel and task-agnostic augmentation strategy that operates in the feature space rather than the image space. NFR learns a transformation function that perturbs intermediate visual features—extracted from a frozen pretrained encoder—by applying semantically consistent but structurally varied modifications guided by a latent random seed. This feature-level augmentation is jointly optimized with the policy learning objective, enabling more robust and generalizable policies for embodied instruction following. Through experiments on long-horizon tasks involving navigation and object manipulation, we demonstrate that NFR significantly improves task success rates, especially under visual variability and limited demonstration scenarios, highlighting its potential as a scalable and adaptive solution for embodied AI applications.
Continuous-Action Reinforcement Learning for Point-Cloud Registration with Curriculum-Driven SE(3) Exploration (김진용)

Point-cloud registration is a core module in modern SLAM and augmented-reality pipelines, yet current RL-based approaches such as ReAgent rely on a discretised 6-DoF action grid that cannot express truly optimal alignment steps and often suffers from axis-wise greedy decisions. We propose a fully continuous action space formulation in which a Gaussian actor outputs real-valued SE(3) updates—three Euler-angle increments and three translations—enabling sub-degree, sub-millimetre corrections that discrete tables cannot reach. To stabilise training across this large space, we introduce a curriculum schedule that gradually widens the allowable rotation range: the agent first learns on pairs rotated within ±10°, then expands the bound in 10° increments up to ±180°, producing a single policy that covers the full orientation spectrum while retaining fine-grained precision. The accompanying critic evaluates joint 6-DoF moves, overcoming ReAgent’s axis-independent optimisation and naturally discovering globally optimal actions. By eliminating resolution bottlenecks and reducing hand-crafted heuristic tuning, our framework promises more reliable, faster convergence in real-time mapping and AR pose-tracking scenarios where robust alignment under wide baselines is critical.
Confidence-Aware Expert-Mixed Reinforcement Learning for the Traveling Salesman Problem (변한준)
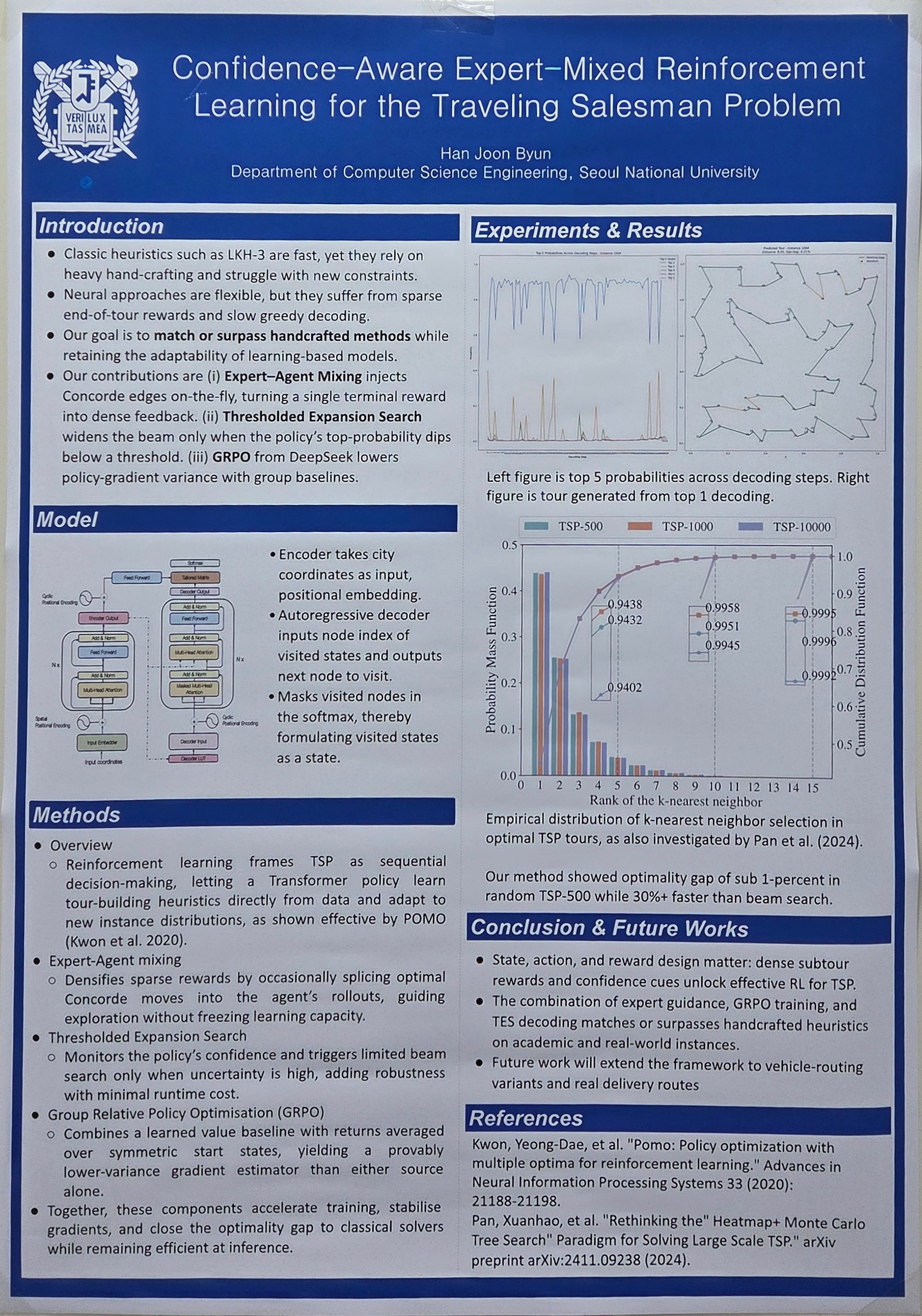
We introduce a confidence-aware, expert-guided reinforcement-learning (RL) solver for the Traveling Salesman Problem (TSP) that marries a principled Markov-decision-process formulation with practical routing performance. A transformer encoder represents the ordered list of visited cities together with (i) a binary mask of remaining nodes and (ii) incremental tour-length features, giving the policy a concise yet complete view of the current context while keeping the action space tractable. To alleviate reward sparsity, we splice optimal subtours from Concorde into the agent’s rollouts, converting final-tour returns into dense shaping signals. Training employs Group Relative Policy Optimisation, a variance-reduced policy-gradient method that exploits the permutation symmetry of TSP instances, while inference uses Thresholded Expansion Search: the beam widens only when the policy’s soft-max confidence drops below a preset level, yielding fast yet reliable decoding. Experiments span (1) random Euclidean instances up to 200 nodes, (2) ten TSPLIB benchmarks, and (3) 2 700 real parcel-delivery routes. Across all settings the proposed solver attains a competitive optimality gap against classical heuristics (LKH-3, 2-Opt, Christofides) and neural baselines (Attention-TSP, POMO). These results demonstrate that, with carefully crafted state, action, and reward definitions, RL can match or surpass handcrafted methods on both academic and real-world TSP variants.
SALT: Sparsity-Aware Latency-Tunable LLM Inference Acceleration (장홍선)

Transformer-based large language models (LLMs) have become the foundation of modern natural language processing (NLP), enabling high-quality, context-aware text generation across a wide range of applications.
However, their deployment in latency-sensitive environments remains challenging due to the quadratic complexity of the attention mechanism.
Recent work on sparse attention has shown promise in mitigating this bottleneck by attending to a subset of tokens, but existing methods typically rely on static sparsity patterns or fixed computational budgets, limiting their adaptability to varying runtime constraints.
However, their deployment in latency-sensitive environments remains challenging due to the quadratic complexity of the attention mechanism.
Recent work on sparse attention has shown promise in mitigating this bottleneck by attending to a subset of tokens, but existing methods typically rely on static sparsity patterns or fixed computational budgets, limiting their adaptability to varying runtime constraints.
In this project, we propose an adaptive sparse attention mechanism that dynamically adjusts the sparsity level during inference based on contextual signals. To this end, we formulate sparsity control as a sequential decision-making problem and leverage simple reinforcement learning (RL) to learn a policy that balances latency and accuracy in real time.
Our experiments demonstrate that determining not only the appropriate sparsity ratio but also the attention pattern for each layer based on runtime context is crucial. By evaluating our method on representative benchmarks, we show that adaptively adjusting the computational budget would enable more effective trade-offs between inference efficiency and output quality.
A Unified Reinforcement Learning Framework for Basic Block Instruction Scheduling (정창훈)
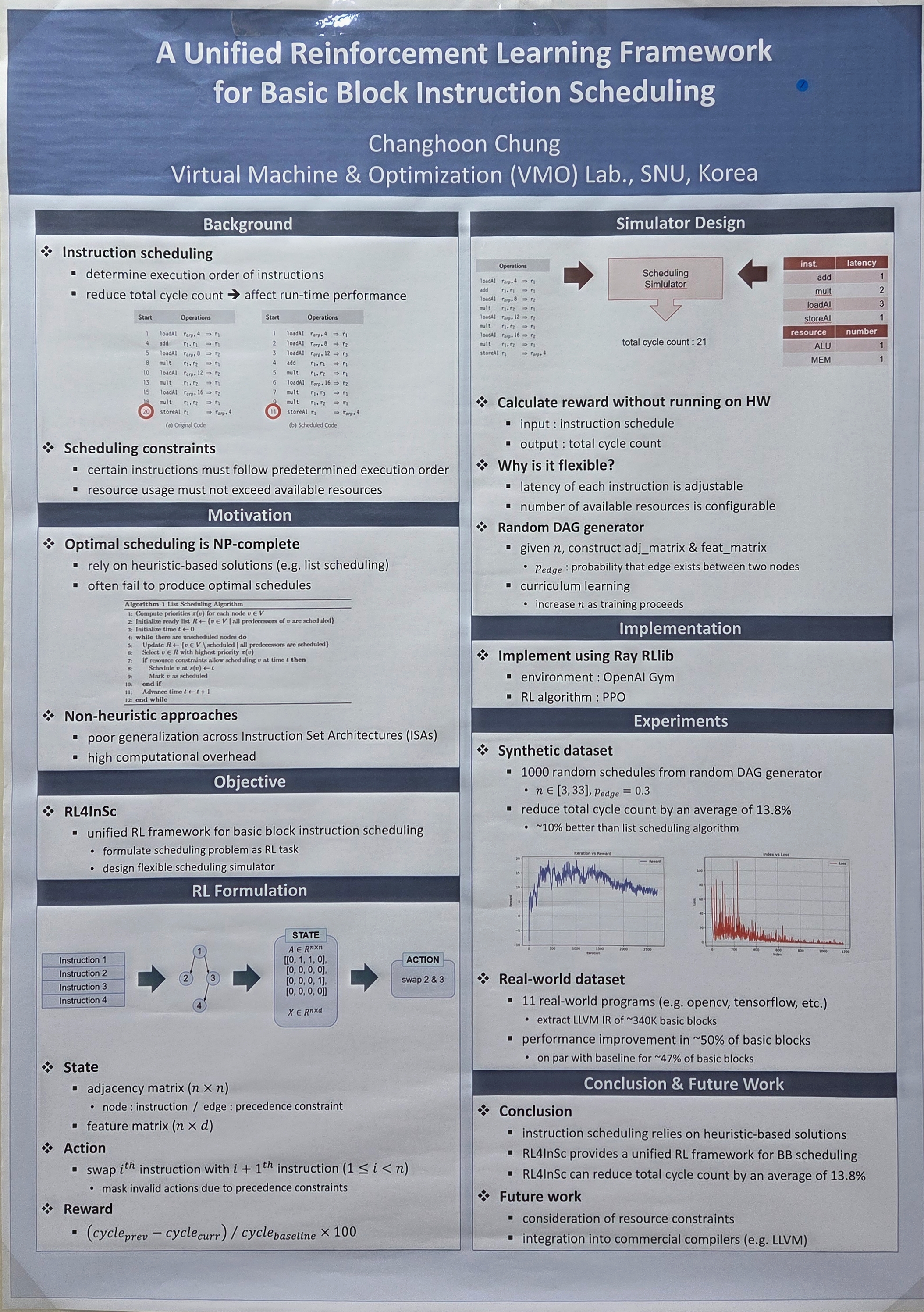
Instruction scheduling is a fundamental compiler optimization that determines the execution order of instructions. By reducing the total cycle count, instruction scheduling can directly affect the run-time performance of compiled binaries. Despite its significance, most commercial compilers rely on heuristic-based strategies, which often fall short of achieving optimal schedules. Although prior research has explored non-heuristic approaches for solving the scheduling problem, these methods typically suffer from high computational overhead or poor generalization across Instruction Set Architectures (ISAs). In this paper, we propose RL4InSc, a unified reinforcement learning (RL) framework for basic block instruction scheduling. Our key contribution lies in formulating the scheduling problem as an RL task, and designing a flexible scheduling simulator that can generalize across diverse ISAs. Experimental results demonstrate that Rl4InSc reduces the cycle count of synthetic basic blocks by an average of 13.8%, and achieves performance improvements in 50% of the basic blocks found in real-world benchmark programs.
Hybrid Coverage Path Planning Using Boustrophedon Decomposition and Reinforcement Learning (한상규)

Coverage Path Planning (CPP) is a fundamental task in autonomous robotics, essential for applications such as cleaning, painting, and excavation. Classical methods like boustrophedon decomposition provide systematic and complete coverage in structured environments but often fail to adapt to local complexities or minimize traversal costs. Reinforcement Learning (RL), by contrast, offers data-driven adaptability but can suffer from sample inefficiency and poor generalization when applied in isolation.
This paper proposes a hybrid CPP framework that integrates boustrophedon decomposition for global map segmentation with local path refinement using deep RL. The RL component is explored through multiple algorithms including Deep Q-Networks (DQN), Proximal Policy Optimization (PPO), and Advantage Actor-Critic (A2C), each evaluated for efficiency and adaptability across different environment layouts.
Baseline comparisons are conducted against (1) standard boustrophedon planning, (2) a handcrafted heuristic local planner, and (3) standalone RL-based planners without decomposition. Experiments on benchmark grid maps with varying obstacle densities demonstrate that our hybrid approach achieves improved path efficiency, fewer turns, and reduced overlap, while maintaining full coverage. The results suggest that combining rule-based structure with learning-based adaptability enables more robust and context-aware coverage strategies for robotic systems.
Empowering LLMs with Strategic Tool Use via Reinforcement Learning (현시은)

Large Language Models (LLMs) excel at natural language tasks but struggle with precise computation, accurate factual retrieval, and structured problem-solving. To overcome these limitations, This paper proposes a reinforcement learning (RL) framework that enables LLMs to strategically leverage external tools—namely, Python code execution with sandboxing and error feedback, as well as Retrieval-Augmented Generation (RAG) for factual knowledge.
Unlike previous methods that rely on static prompts or supervised training alone, our approach trains LLMs dynamically through interactive, feedback-driven episodes, allowing the model to autonomously learn optimal tool invocation policies.
We begin with supervised fine-tuning on curated reasoning examples augmented with tool use to establish a foundational understanding. Then, we apply Proximal Policy Optimization (PPO) to iteratively refine the model’s strategic reasoning through real-time interactions, substantially enhancing task-specific performance. Experimental evaluations on challenging benchmarks—including mathematical problem-solving (AIME) and scientific question answering (ARC Challenge)—show that LLMs trained with RL effectively self-correct, selectively use tools, and significantly outperform conventional models in both accuracy and reasoning robustness.
This work underscores the potential of combining reinforcement learning with targeted tool integration, paving the way for more accurate and reliable LLM applications in complex reasoning and real-world scenarios.
Unlike previous methods that rely on static prompts or supervised training alone, our approach trains LLMs dynamically through interactive, feedback-driven episodes, allowing the model to autonomously learn optimal tool invocation policies.
We begin with supervised fine-tuning on curated reasoning examples augmented with tool use to establish a foundational understanding. Then, we apply Proximal Policy Optimization (PPO) to iteratively refine the model’s strategic reasoning through real-time interactions, substantially enhancing task-specific performance. Experimental evaluations on challenging benchmarks—including mathematical problem-solving (AIME) and scientific question answering (ARC Challenge)—show that LLMs trained with RL effectively self-correct, selectively use tools, and significantly outperform conventional models in both accuracy and reasoning robustness.
This work underscores the potential of combining reinforcement learning with targeted tool integration, paving the way for more accurate and reliable LLM applications in complex reasoning and real-world scenarios.
Isoform-aware long-read sequence alignment using deep reinforcement learning (황현서)
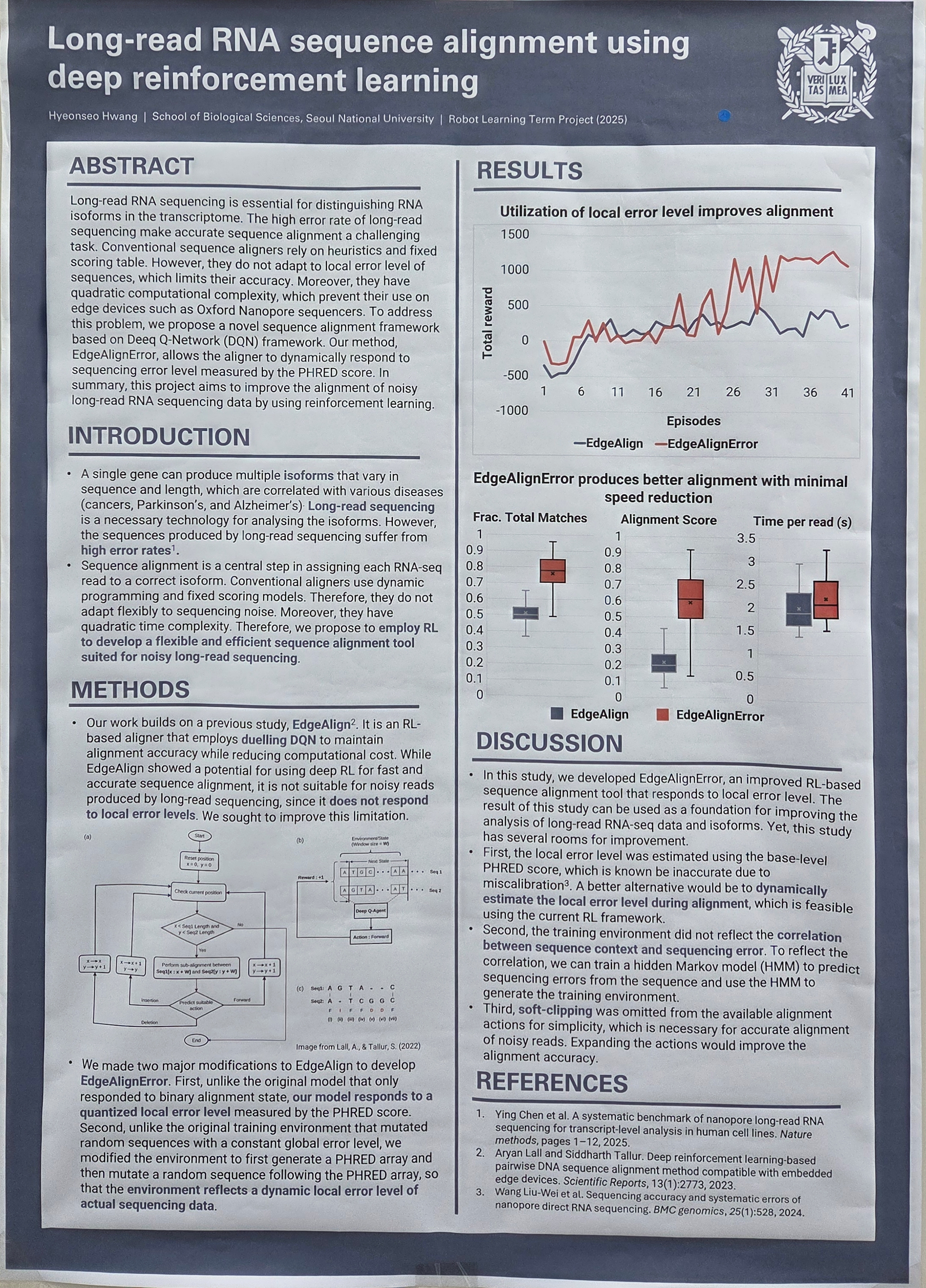
Long-read RNA sequencing is essential for distinguishing RNA isoforms in the transcriptome. However, the high error rate of long-read sequencing and high similarity between isoforms make accurate isoform assignment a challenging task. Conventional sequence aligners rely on heuristics and fixed scoring table, so they cannot accurately assign isoforms over the whole transcriptome. To address this problem, we propose a novel isoform-aware sequence alignment framework based on Proximal Policy Optimization (PPO) framework. Our method allows the aligner to dynamically respond to local sequence context and sequencing error level. The model is also aware of annotated and predicted splice sites, enabling accurate isoform assignment. In summary, this project aims to to improve isoform assignment in noisy long-read RNA sequencing data by using reinforcement learning.
Vision-based Active 3D Reconstruction for Large-scale Scene with a Deep Reinforcement Learning (신제민)

Accurate 3D reconstruction is critical in domains such as construction, urban planning, and autonomous navigation, especially in large-scale outdoor environments. Traditional UAV-based reconstruction systems typically rely on predefined flight paths, often resulting in incomplete scene coverage due to occlusions and complex geometries. To address this, we propose a monocular vision-based active 3D reconstruction framework that enables adaptive viewpoint selection using deep reinforcement learning (DRL). Unlike existing methods that depend on depth sensors—which are impractical for UAV deployment in outdoor settings—our approach leverages only monocular RGB images. The system formulates viewpoint planning as a Markov Decision Process, where the UAV selects viewpoints to maximize reconstruction completeness based on surface coverage improvement. The framework comprises four core modules: monocular 3D reconstruction, coverage estimation, DRL-based viewpoint policy, and a training-to-deployment pipeline. Training is conducted in simulation using ground-truth 3D models for reward computation, while real-world deployment relies on proxy reward metrics. Experimental evaluation in simulated environments demonstrates superior performance over baseline methods in terms of reconstruction quality and efficiency. An ablation study further investigates the impact of reward design, DRL algorithms, and sensor modalities. This research highlights the potential for deploying active monocular 3D reconstruction in real-world UAV applications.