
Project
Information
- Date: 2024/06/12 (Wednesday)
- Time: 3:30PM- 5:30PM
Schedule
- 3:30 PM ~ 3:45 PM: Session 1 Presentation
- 3:45 PM ~ 4:05 PM: Session 1 Poster Session
- 4:05 PM ~ 4:20 PM: Session 2 Presentation
- 4:20 PM ~ 4:40 PM: Session 2 Poster Session
- 4:40 PM ~ 4:55 PM: Session 3 Presentation
- 4:55 PM ~ 5:15 PM: Session 3 Poster Session
Algorithmic Foundations of RL
- Adaptation of Contrastive Initial State Buffer for Reinforcement Learning (Hannes Melchoir Buechi)
- Efficient RL via Quantization (Jihun Kang)
- PILOT: Preference-based Imitation Learning via Refining Offline Dataset (Hyeokjin Kwon)
- Trajectory Transformer with Sparse Attention (Minsoo Kim)
- Learning skills for efficient adaptation to new environments and tasks (Sunwoo Kim)
- Intention-Aware Cross-Domain Skill Transfer via Joint Skill Discovery (Junseok Kim)
- Q-learning with Parameterized Convex Minorant and Its Interpretation in Actor-Critic Perspective (Hyungjo Byun)
- Adaptive Clipping in Proximal Policy Optimization (Subin Shin)
- Improving Training Efficiency of REINFORCE Algorithm through Gradient Variance Reduction Techniques (Yohan Yoon)
- Discovering and Generalizing Novel Skills through Multi-Objective Inverse Reinforcement Learning (Junseo Lee)
- Uncertainty-based Dueling DQN with Reward Back-propagation (Yumin Lim)
- Adversarial Environment Design via Regret-Guided Diffusion Models (Hojun Chung)
- Reward based basis ensemble MAML (Joonho Han)
RL for Robotics
- Pedestrian Collision Avoidance for Autonomous Vehicles: Deep Reinforcement Learning and MPC Integration in CARLA Simulator (Yunyoung Kook)
- Guided exploration reinforcement learning for 3D UAV pursuit-evasion games (Dohyun Kim)
- Comparative Analysis of Constraint Safe Reinforcement Learning Application on Minimal Risk Maneuver in Autonomous Vehicle (Jaejoon Kim)
- Comparison of deterministic and stochastic policy reinforcement learning for ankle-foot orthosis control (Jaehyeon Kim)
- Enhancing Autonomous Ship Navigation: Integrating Sensor Reliability in Deep Reinforcement Learning (Saeyong Park)
- Solving Online 3D Bin Packing Problem with Realistic Buffer (Yoseph Park)
- Model Predictive Control based Residual Reinforcement Learning for Autonomous Racing in Simulation (Sungpyo Sagong)
- Environment-Constrained Robot Navigation Using Deep Reinforcement Learning for Crowded Scenarios (Yeongin Yoon)
- Rapidly-Exploring Random Tree with Reinforcement Learning Based Sampling (Jaewon Lee)
- Lyapunov-guided Control of Quadrotor UAVs Based on Deep Reinforcement Learning Approach (Jiwon Lee)
- Efficient Reinforcement Learning for Autonomous Racing with Imperfect Demonstrations (Heeseong Lee)
- Leveraging Equivariant Representations of 3D Point Clouds for SO(3)-Equivariant 6-DoF Grasp Pose Generation (Byeongdo Lim)
- Trajectory Tracking Control for Autonomous Racing Based on Tube-MPC and LSTM-DDPG Algorithm (Myeonggeun Jeon)
RL for AI Systems
- Face hallucination with multi-agent reinforcement learning (Anh Thi Luu)
- Adversarial Approach to Conditioned Synthesis of Character-Scene Interaction (Jeonghwan Kim)
- Mimicking 3D Motion with Human-Object Interaction from 2D (Hyeonwoo Kim)
- RLRM : Single Image 3D Reconstruction Model using Reinforcement Learning (Sangwon Baek)
- Generate Diverse Character Physics Motion using Deep Reinforcement Learning (Wonjeong Seo)
- Link Prediction via Reinforcement Learning (Euisang Lee)
- Versatile Physics-based Character Control with Hybrid Latent Representation (Donggeun Lim)
- Zero-shot LTL learning through embedding generalization (Wonhyung Jung)
- Hierarchical Reinforcement Learning for Dynamic Berth Allocation Problems (Seongbae Jo)
- Road Graph Attention Model: Solving Pickup and Delivery Problem on Road Graph Environment (Geunje Cheon)
- Study on Interpretability of Reinforcement Learning using Kolmogorov-Aronld Networks (Jaeseok Joo)
- Input design method based on observability of nonlinear systems with uncertainty (Deuksun Hong)
- Anti-Agent: Learn from another agent's mistakes (Euikyun Jung)
1. Algorithmic Foundations of RL
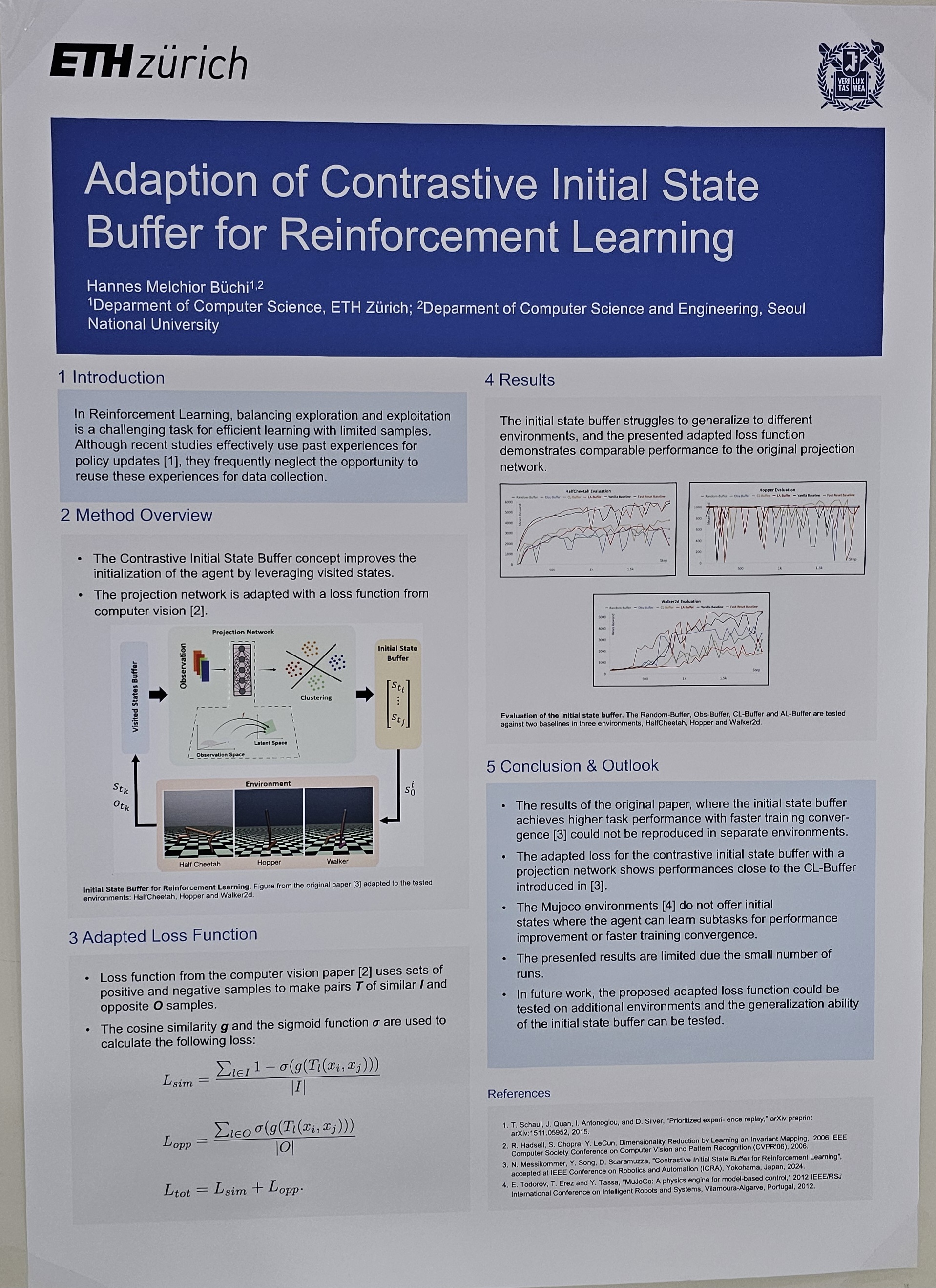
In Reinforcement Learning, balancing exploration and exploitation is a challenging task for efficient learning with limited samples. Although recent studies effectively use past experiences for policy updates, they frequently neglect the opportunityto reuse these experiences for data collection. The Contrastive Initial State Buffer concept is introduced which selects states from past experiences and leverages them for the initialization of the agent in the environment. The concept that uses a projection network to embed states with similar task relevance is adapted with a loss function from computer vision and evaluated in three Mujoco environments, the HalfCheetah, the Hopper and the Walker2d. The initial state buffer struggles to generalize to different environments, and the presented adapted loss function demonstrates comparable performance to the original projection network. |
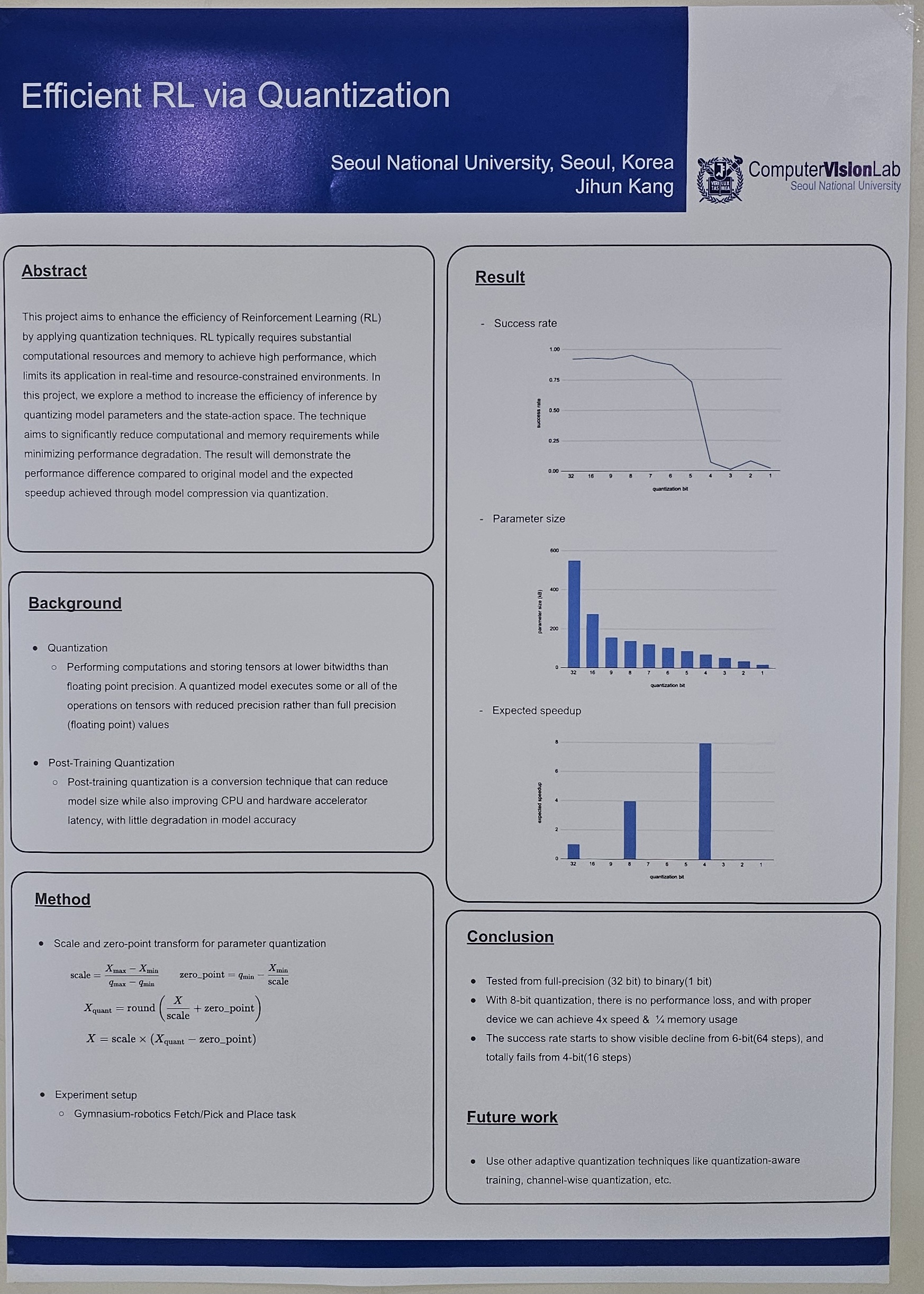
This project aims to enhance the efficiency of Reinforcement Learning (RL) by applying quantization techniques. RL typically requires substantial computational resources and memory to achieve high performance, which limits its application in real-time and resource-constrained environments. In this project, we explore a method to increase the efficiency of inference by quantizing model parameters and the state-action space. The technique aims to significantly reduce computational and memory requirements while minimizing performance degradation. The result will demonstrate the performance difference compared to original model and the expected speedup achieved through model compression via quantization. |

Imitation learning (IL) offers an appealing alternative to reinforcement learning (RL) but struggles with mixed-quality dataset. Preference-based Reinforcement Learning (PbRL) addresses this challenge but requires continuous human feedback. To overcome these limitations, we introduce PILOT, a novel approach that leverages Generative Adversarial Imitation Learning (GAIL) on mixed-quality dataset. PILOT iteratively refines datasets, progressively improving performance by eliminating lower-quality trajectories. It trains a reward function with minimal preference data and pseudo-label made by discriminator which is semi-supervised learning. This enables efficient imitation learning with minimal human intervention, demonstrated through experiments. PILOT bridges the gap between PBRL and IL, promising advancements in complex environments with reduced human input while achieving efficient imitation learning. |
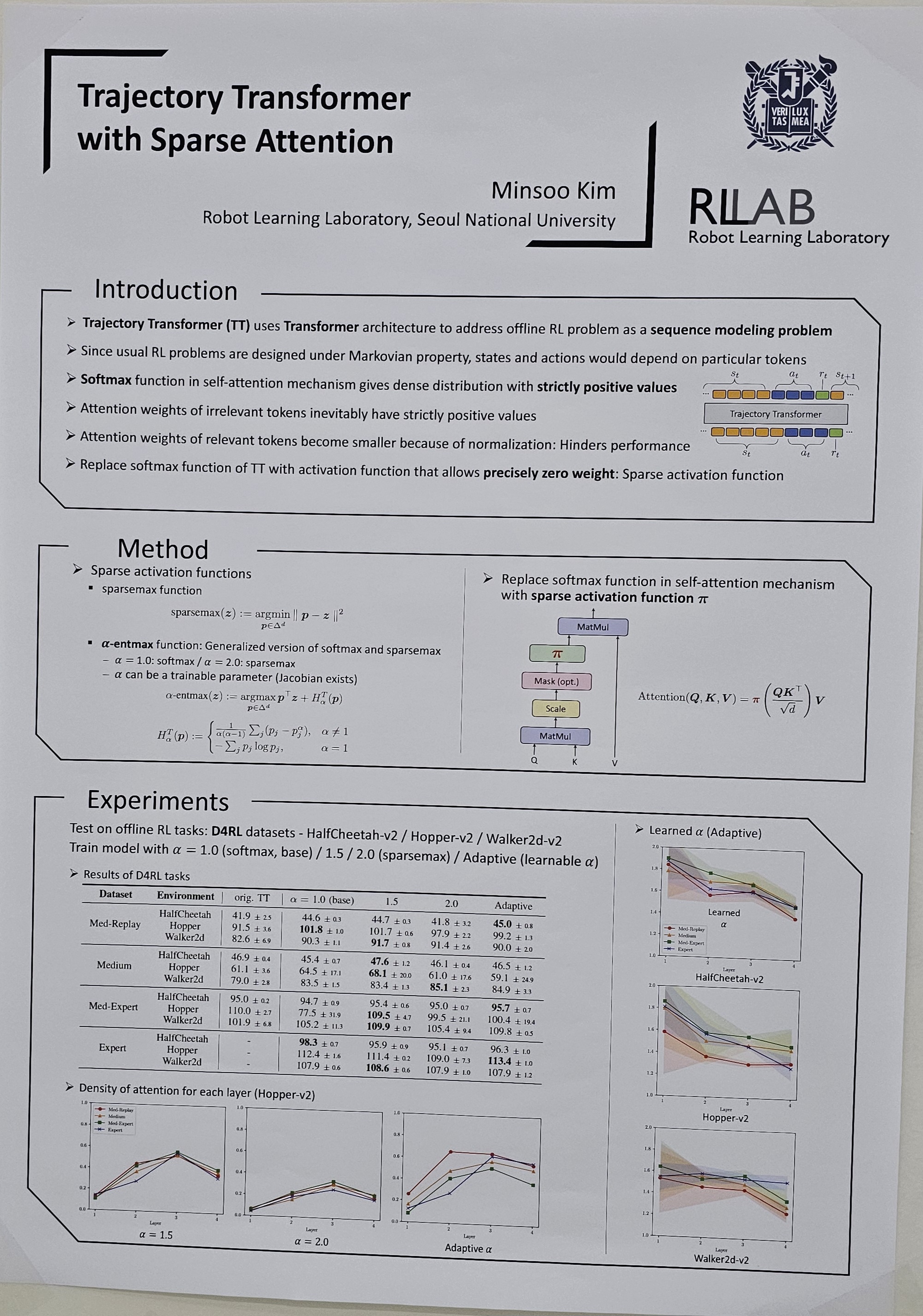
Viewing the Reinforcement Learning (RL) problem as a sequence modeling problem is charming since it omits the designing process of RL algorithms. Trajectory Transformer shows considerable promise in offline RL settings by addressing RL problems with auto-regressive sequence prediction. Attention masks of the self-attention mechanism used in Transformer architecture show that Trajectory Transformer is able to learn characteristics similar to Markovian properties. However, the softmax function, which is an activation function for self-attention inevitably gives a dense distribution with strictly positive outputs. Dense attention can hinder tokens from focusing on more relevant tokens. In this paper, the Trajectory Transformer with sparse attention is proposed by adopting a sparse activation function: α-entmax, instead of the dense softmax function. State and action tokens can concentrate on potentially more relevant states and actions, predicting the next action better. Experimental results show it can learn better in offline RL settings, D4RL tasks, when the datasets consist of immature episodes. |

Hierarchical reinforcement learning enable to manage complex decision-making processes more efficiently, breaking down tasks into manageable sub-tasks that can be learned and optimized independently. One popular category of methods is to discover skills by maximizing behavioral mutual information(MI). However, recent line of works point out MI maximization less encourage dynamic skills, suggesting distance-aware methods. Another orthogonal line of work is discovering options based on graph Laplacian of the MDP for temporally-extended exploration. Such options can be combined with option keyboard for composition of learned options for hierarchical RL. While motivated from these prior work, we aim to solve a more focused problem: learning skills that can be transferred to novel environments and tasks. While previous works focus on adapting to new tasks, they less focus on tackling problems in new environments. By using distributional predictions of the successor features for learning eigenoptions and leveraging randomization while training motivated by domain randomization in sim-to-real transfer, we specifically target this problem on adaptability and trasferability of skills. This research aims to provide a direction for future works on scalable framework for developing AI systems capable of operating effectively in dynamic and unpredictable real-world settings. |

Imitation learning (IL) is a pivotal strategy within robotics, enabling the acquisition of complex behaviors through expert demonstrations. However, the traditional IL paradigm is heavily reliant on pre-existing expert demonstrations, which are often costly and labor-intensive to obtain. To address this, significant research has been directed toward cross-domain imitation learning (CDIL), which leverages expert knowledge from diverse domains to enable skill transfer across different environments, dynamics, and embodiments. We introduce a novel framework that not only reduces dependence on expert demonstrations by facilitating policy transfer across multiple domains but also incorporates intention-aware capabilities. This enhancement allows the system to recognize and replicate specific intentions such as crawling or bipedal walking, addressing the under-defined nature of CDIL challenges. Our methodology utilizes an unsupervised reinforcement learning framework, optimizing it to maximize the conditional mutual information between states in different domains, given a specific skill. This is achieved by aligning latent vectors that represent distinct skills. Experimental validation is performed in two distinct scenarios: (1) Human Motion Driven Control (HMDC), where predefined skills such as walking, crauching, jumping, and turning actions of a humanoid are transferred to the quadruped robot Go1; and (2) the development of a generalist transfer framework that can adapt any specified policy at inference time, through learning in a fully online manner with heterogeneous robots. |
Q-learning with Parameterized Convex Minorant and Its Interpretation in Actor-Critic Perspective (Hyungjo Byun)
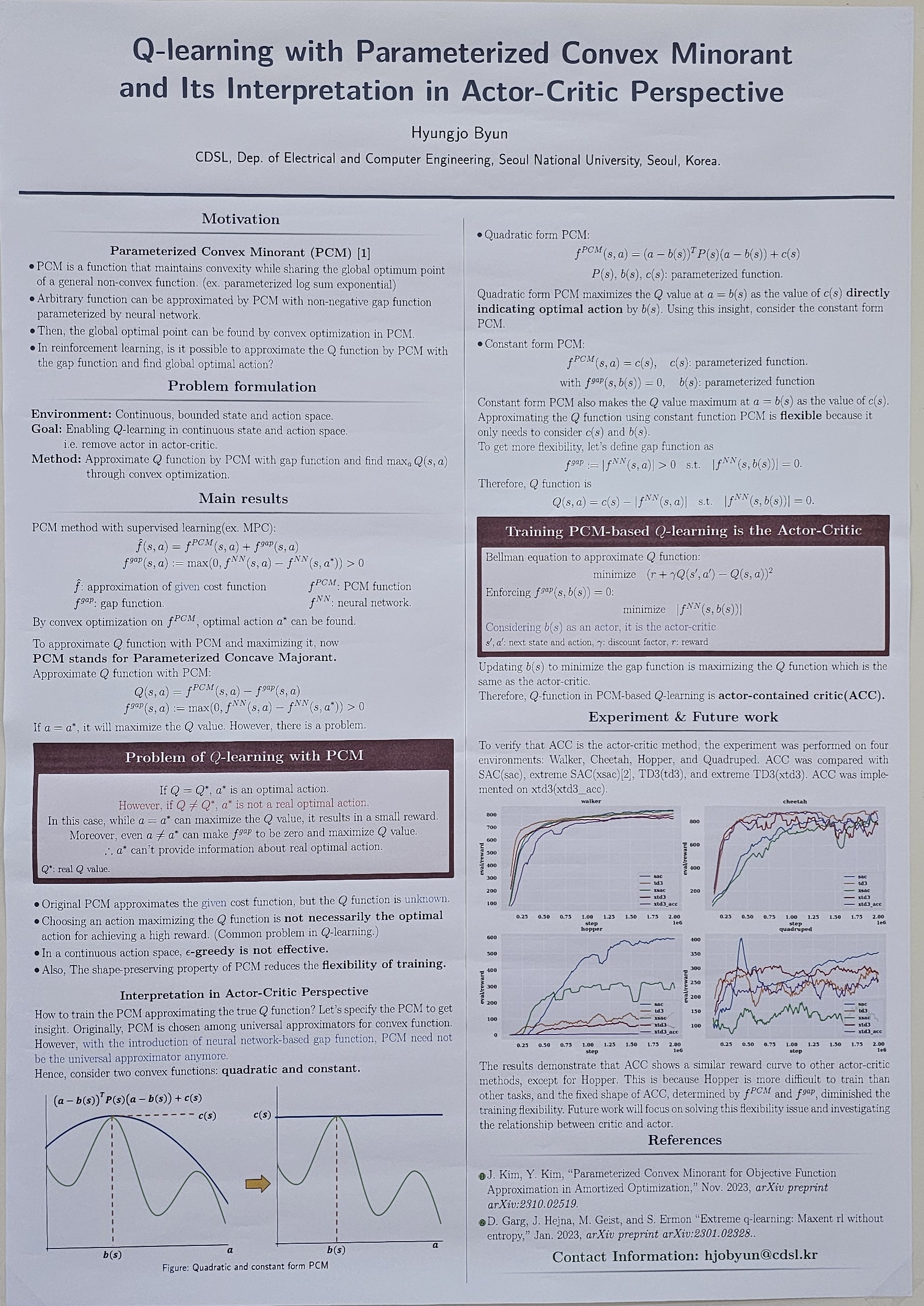
With advancements in computational speed and convex optimization technology, a parameterized convex minorant method has been proposed to find a convex function that shares common global optimal point with general non-convex functions using neural networks. This approach has been effectively utilized in supervised learning by training a given cost function. However, its application in Q-learning, which requires the exploration of cost functions, has not been studied. This paper addresses the challenges of applying parameterized convex minorants to Q-learning, particularly extreme Q-learning, and finds that the solution to overcoming these difficulties is similar to the actor-critic method. This finding can propose a new perspective on Q-learning and actor-critic methods, identifying key factors for successful training in actor-critic frameworks. |

Proximal policy optimization(PPO) is a policy gradient reinforcement learning method that uses a clipping term in its surrogate objective function. This helps prevent dramatic policy updates and stabilize the learning process. In its policy update mechanism, PPO uses a fixed hyperparameter ϵ which is typically set heuristically through experiential insights. Fixing ϵ throughout the whole learning process can lead to some issues. It may lead to more frequent policy updates for less important states than necessary, since policy update for important state often vanishes early when probability ratios exceed the clipping threshold. Also, even if the policy is converging, it does not ensure that the updates become progressively smaller with each epoch to maintain stability and improve learning efficiency. To handle these issues, we propose an adaptive approach to determine the clipping threshold ϵ using neural network trained end-to-end. ϵ is dynamically adjusted based on the state importance and epoch progression. Adaptive ϵ driven from ϵ-network allows significant updates for important states and smaller changes for less important ones. Additionally, adaptive ϵ can be gradually decreased to reduce update scales adaptively, enhancing learning stability and efficiency ensuring significant updates for critical states while maintaining stability. |
Improving Training Efficiency of REINFORCE Algorithm through Gradient Variance Reduction Techniques (Yohan Yoon)
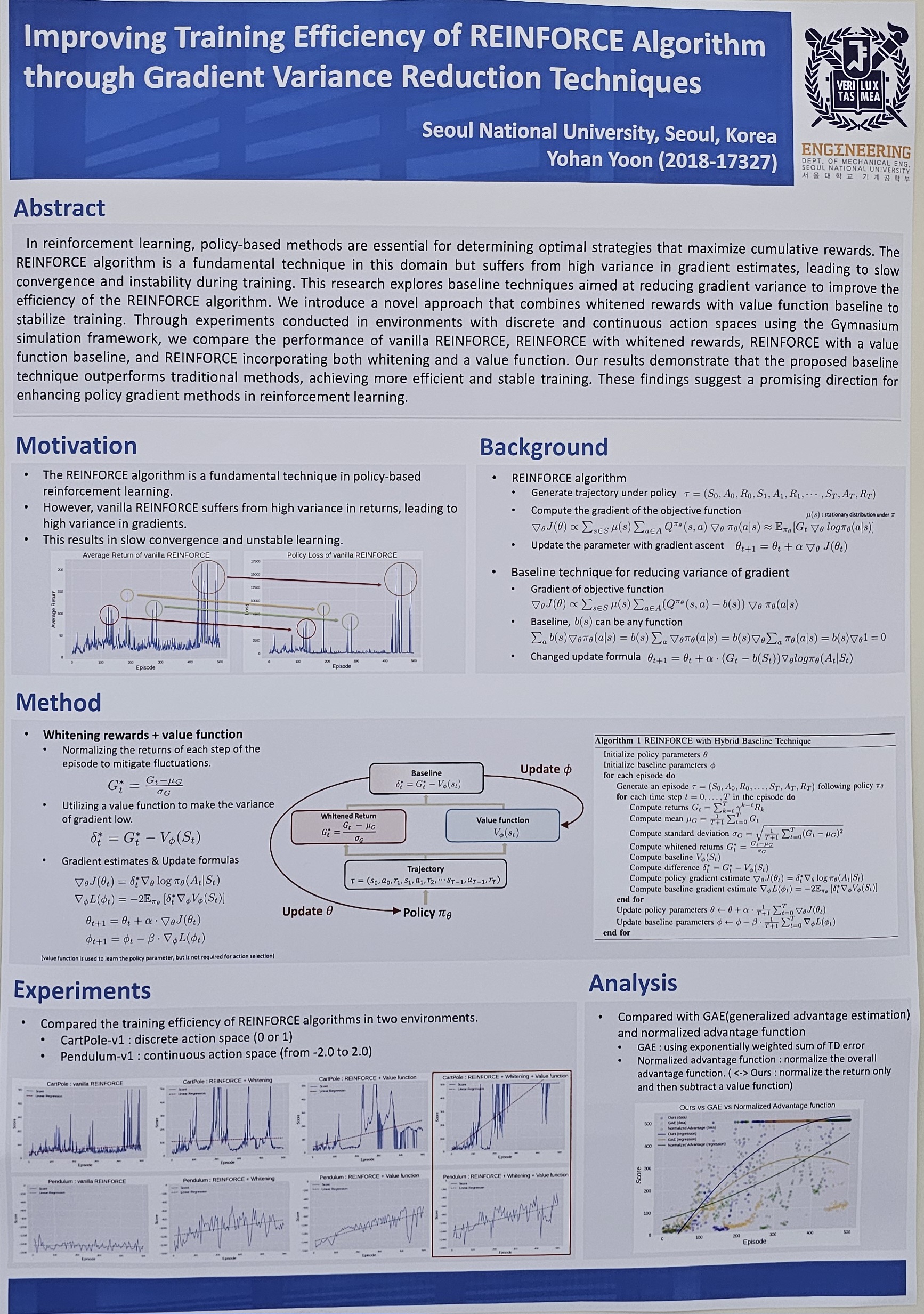
In reinforcement learning, policy-based methods are essential for determining optimal strategies that maximize cumulative rewards. The REINFORCE algorithm is a fundamental technique in this domain but suffers from high variance in gradient estimates, leading to slow convergence and instability during training. This research explores baseline techniques aimed at reducing gradient variance to improve the efficiency of the REINFORCE algorithm. We introduce a novel approach that combines whitened rewards with value function baseline to stabilize training. Through experiments conducted in environments with discrete and continuous action spaces using the Gymnasium simulation framework, we compare the performance of vanilla REINFORCE, REINFORCE with whitened rewards, REINFORCE with a value function baseline, and REINFORCE incorporating both whitening and a value function. Our results demonstrate that the proposed baseline technique outperforms traditional methods, achieving more efficient and stable training. These findings suggest a promising direction for enhancing policy gradient methods in reinforcement learning. |
Discovering and Generalizing Novel Skills through Multi-Objective Inverse Reinforcement Learning (Junseo Lee)
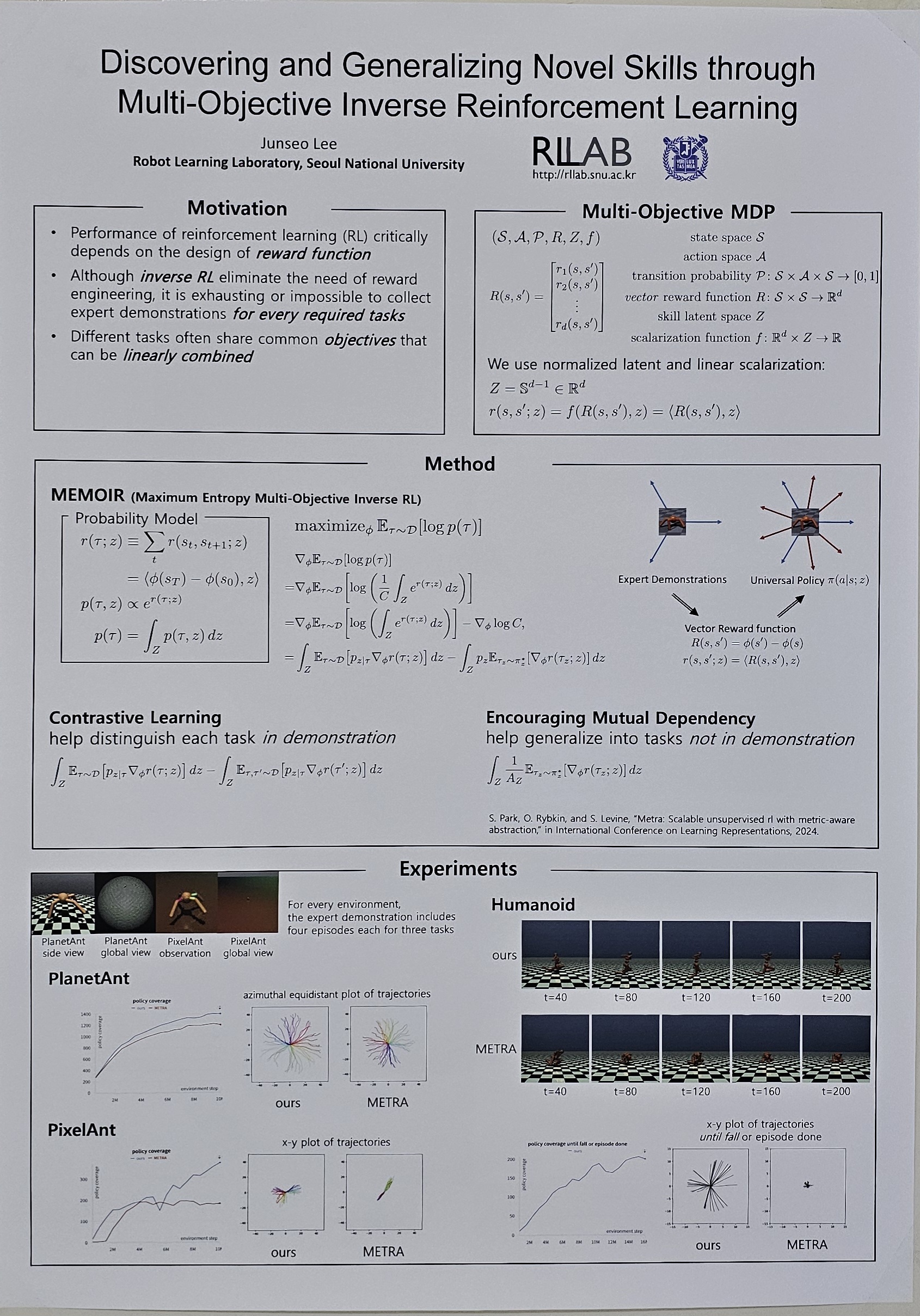
Unsupervised reinforcement learning and inverse reinforcement learning techniques enable meaningful tasks to be learned without predefined reward functions. On this foundation, we propose "Maximum Entropy Multi-Objective Inverse Reinforcement Learning" (MEMOIR), a novel framework that constructs vector reward function for discovering and generalizing useful skills guided by unlabeled multi-objective demonstrations. This approach optimizes a universal policy for diverse skills by extending the maximum entropy inverse reinforcement learning paradigm into multi-objective settings. Through extensive experiments, MEMOIR has demonstrated its efficiency in discovering novel skills not present in demonstrations, even for complex tasks that are typically challenging without intricate reward engineering. The proposed method generalizes from demonstrations, learning to perform tasks beyond the observed behaviors with minimal supervision. |

We address the sparse reward problem and the difficulty in distinguishing between similar action values in Dueling DQN. To tackle the sparse reward problem, we implement a reward back-propagation strategy, while for the difficulty in distinguishing between similar action values, we propose uncertainty-based method. This involves introducing a separate network to predict the uncertainty of action values, enabling probabilistic learning. Our objective is to ensure that the uncertainty network outputs represent reliability. We further enhance learning efficiency by modifying and propagating rewards backward. Overall, our method effectively tackles these challenges, significantly improving the performance of Dueling DQN. |
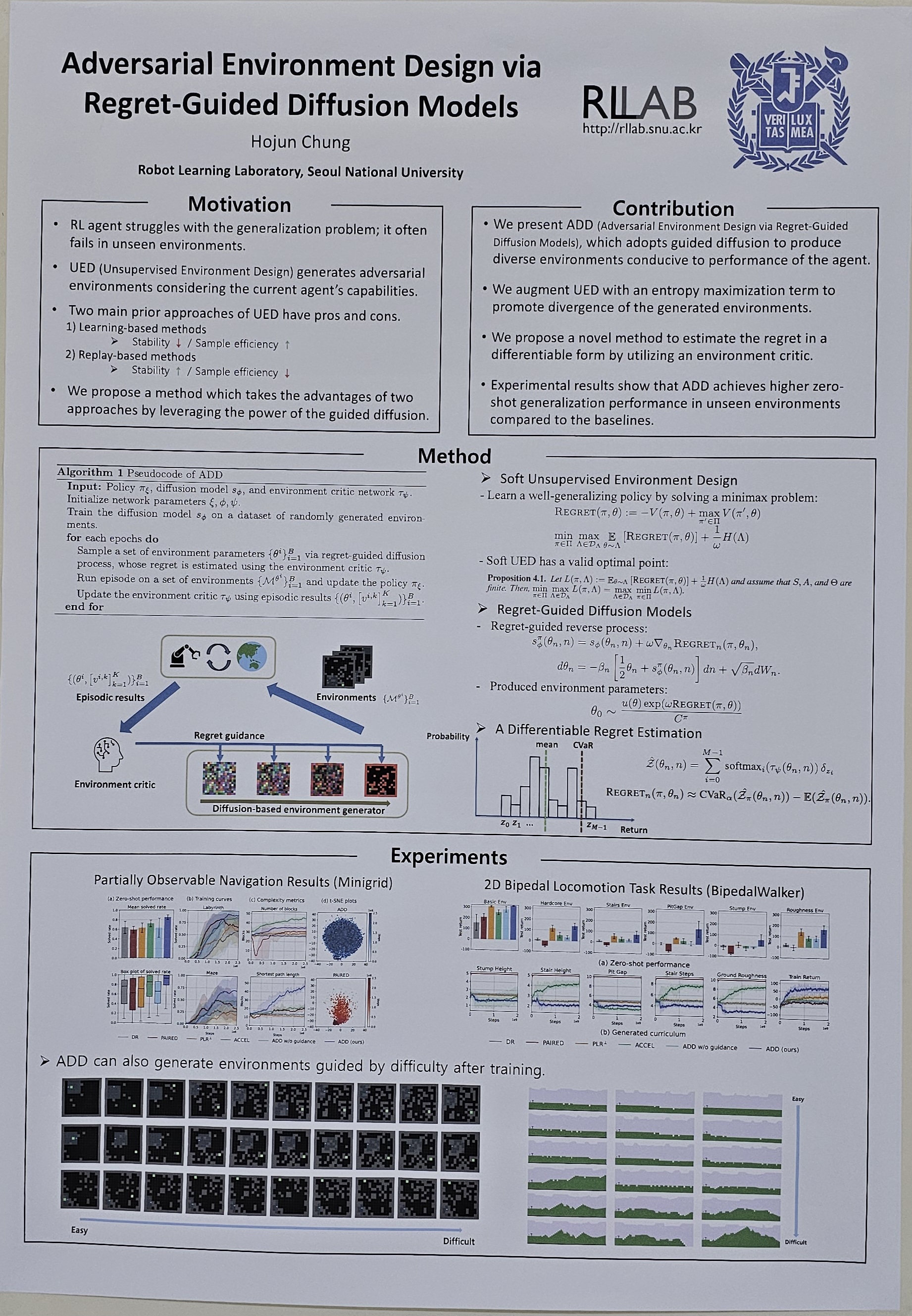
Training agents that are robust to environmental changes remains a significant challenge in deep reinforcement learning (RL). Unsupervised environment design (UED) has recently emerged to address this issue by generating a set of training environments tailored to the agent's capabilities. While prior works demonstrate that UED has the potential to learn a robust policy, their performance is constrained by the capabilities of the environment generation. To this end, we propose a novel UED algorithm, adversarial environment design via regret-guided diffusion models (ADD). The proposed method guides the diffusion-based environment generator with the regret of the agent to produce environments that the agent finds challenging but conducive to further improvement. By exploiting the representation power of diffusion models, ADD can directly generate adversarial environments while maintaining the diversity of training environments, enabling the agent to effectively learn a robust policy. Our experimental results demonstrate that the proposed method successfully generates an instructive curriculum of environments, outperforming UED baselines in zero-shot generalization across novel, out-of-distribution environments. |
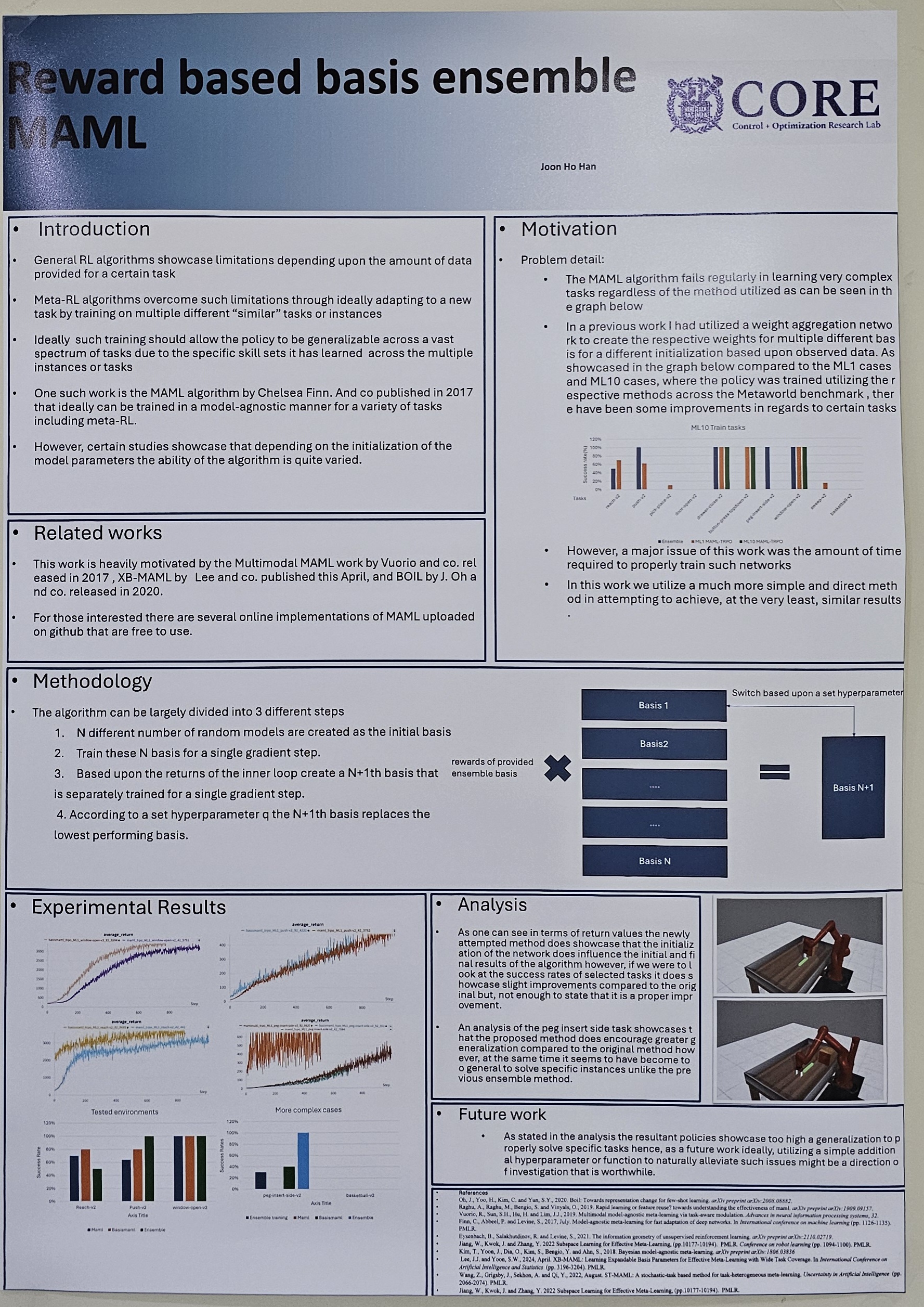
Reinforcement learning algorithms ideally attempts to optimize a policy for different tasks regardless of the scarcity of information or the initialization of the policy parameters. However, several different studies showcase that for certain algorithm and task pairs the successful completion of the task is observed. There have been several different attempts to solve this method in various ways such as applying an external network to help initialize the policy parameters towards the specified task. In this paper I demonstrate , although it may have not been as successful as one would hope, a further work upon the MAML[1] algorithm where the initialization of the policy parameters are calculated through an ensemble method where the weights applied to each sub-basis is calculated according to the rewards calculated by their respective trajectories. Furthermore, these sub-basis are consistently updated with the new created policies according to set hyper parameters. Although not as successful as hoped the work is tested upon several different METAWORLD[2] benchmarks ,unlike previous similar works, that have been known to showcase failure in training when utilizing MAML[1] algorithms ,and these results showcase that through utilization of ensemble methods and different initialization methods even tasks that were nearly impossible for the MAML[1] algorithm to solve is solvable. |
2. RL for Robotics
Pedestrian Collision Avoidance for Autonomous Vehicles: Deep Reinforcement Learning and MPC Integration in CARLA Simulator (Yoonyoung Cook)

Autonomous vehicles (AVs) have garnered significant attention due to their potential to revolutionize transportation by enhancing safety and efficiency. However, ensuring pedestrian safety remains a critical challenge for AVs, especially in complex urban environments. In this project, an approach for pedestrian collision avoidance using the CARLA simulator is proposed, integrating reinforcement learning (RL) with model predictive control (MPC). The method uses RL algorithms, specifically Recurrent Proximal Policy Optimization (RecurrentPPO), to learn pedestrian interaction behaviors and navigate dynamic environments. By training the AV in simulated scenarios, it can adaptively respond to pedestrian movements and avoid collisions effectively. Furthermore, the performance of RecurrentPPO is compared with other RL algorithms such as Deep Q-Networks (DQN) and Soft Actor-Critic (SAC) to evaluate their efficacy in pedestrian collision avoidance tasks. Additionally, the integration of MPC for trajectory planning and control is investigated, complementing RL-based decision-making with predictive control strategies. Through extensive experiments and evaluations in the CARLA simulator, the effectiveness and robustness of the proposed approach in ensuring pedestrian safety while maintaining efficient AV navigation are demonstrated. The findings provide valuable insights into the integration of RL and MPC for enhancing AV pedestrian collision avoidance systems, contributing to the advancement of autonomous driving technologies. |
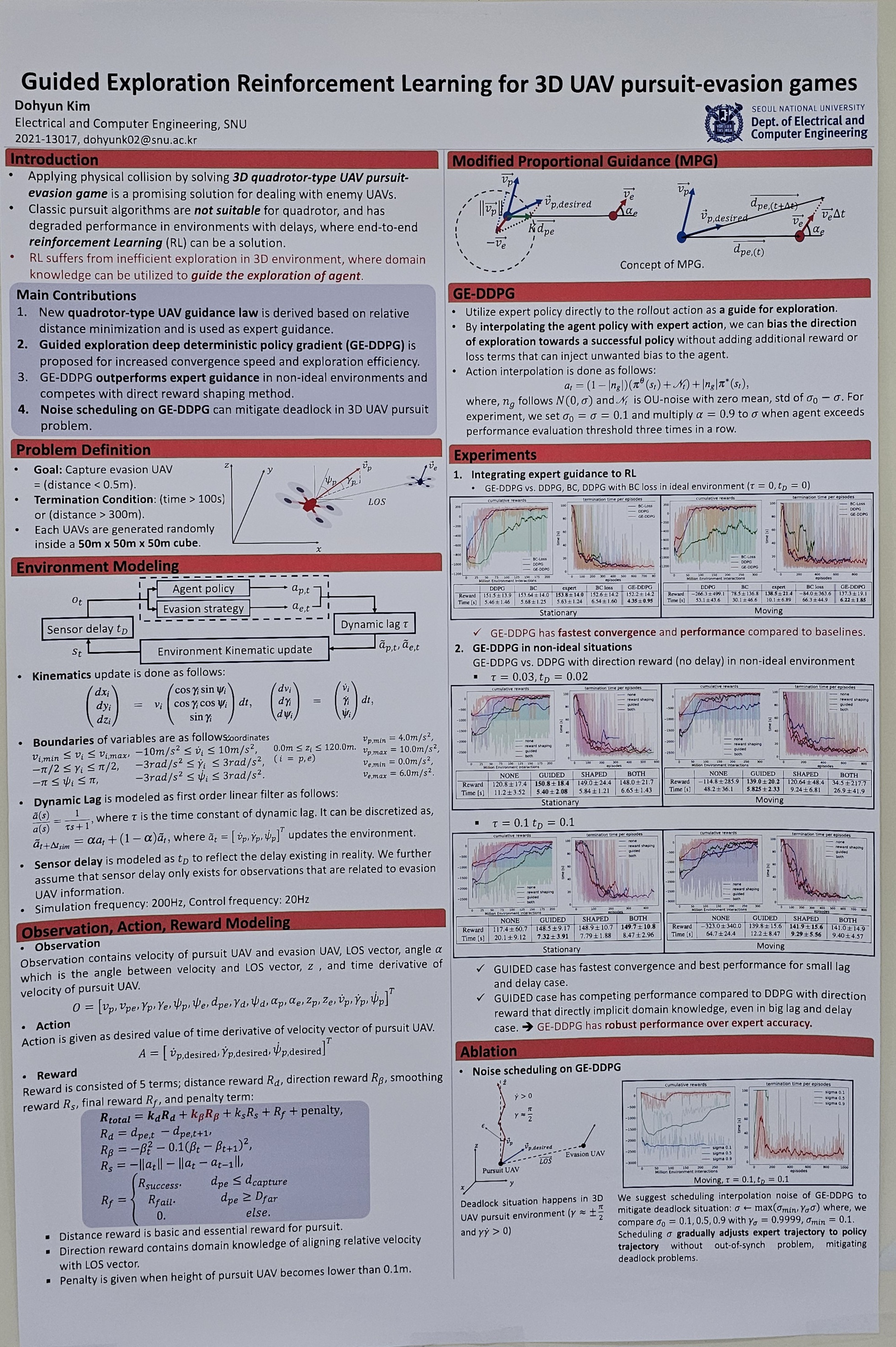
With the increasing usage of UAV in modern warfare, chasing down the enemy UAV with quadrotor and applying physical collision has become a promising countermeasure to cope with enemy UAVs. This emphasizes the urgency of solving UAV 3D pursuit-evasion games. Environment of UAV pursuit-evasion game consists non-ideal factors and moving target situations where classic pursuit algorithms like proportional navigation guidance (PNG) have degraded performance. Therefore, we propose a guided exploration reinforcement learning framework to solve a quadrotor type UAV 3D pursuit-evasion problem. We implemented a 3D UAV pursuit-evasion environment considering dynamic lag and sensor delay to increase realism of the simulation, and derived a new guidance law based on relative distance minimization for expert guidance of quadrotor-type UAV. Then, by guiding the exploration of agent using expert knowledge, we were able to obtain a superior pursuit policy than the expert guidance. We make three contributions; (i) we show that the proposed method has increased convergence and performance compared to baseline algorithms including DDPG, BC and DDPG with BC loss and have superior performance over expert guidance for both stationary and moving evasion UAV situations. (ii) We demonstrate that guided exploration maintains effectiveness and reliability with degraded expert accuracy in non-ideal environment, having competing performance with the case using shaped reward that directly implicit exact state information of relative velocity and direction of line of sight. (iii) We analyze deadlock situation in 3D pursuit environment and suggest noise scheduling to overcome learning failure which can be further viewed as an effective policy transfer metho |
Comparative Analysis of Constraint Safe Reinforcement Learning Application on Minimal Risk Maneuver in Autonomous Vehicle (Jaejoon Kim)

The increasing demand for autonomous vehicles marks a significant transformation in transportation, promising enhanced mobility and convenience. However, ensuring safety, particularly in emergency situations, remains a paramount concern. This paper explores the application of reinforcement learning (RL) techniques to enable autonomous vehicles to perform Minimal Risk Maneuvers (MRM) effectively, achieving a Minimal Risk Condition (MRC). Traditional MRM algorithms often lack the adaptability needed for real-world scenarios. By leveraging advanced RL algorithms such as Soft Actor-Critic (SAC), Twin Delayed Deep Deterministic Policy Gradient (TD3), and Deep Deterministic Policy Gradient (DDPG), integrated with constrained exploration and constrained policy training, this study aims to embed safety constraints directly into the learning process. A comparative analysis of these algorithms within a safe RL framework is conducted using MATLAB, focusing on their effectiveness in MRM fallback scenarios. The results provide insights into the strengths and limitations of each approach, contributing to the development of more robust and adaptive MRM strategies for autonomous vehicle safety. |
Comparison of deterministic and stochastic policy reinforcement learning for ankle-foot orthosis control (Jaehyeon Kim)
Lower limb exoskeleton robots are getting attention for their active support on the gait cycle of users with stability. Many research have been conducted to provide proper control methods of these robots and evaluate the performance of them. However, results are highly variant depending on experiment setup and the experiments cost high. Furthermore, model based control method with static optimization is compute-intensive. Recent research have solved these problems by conducting experiments in simulated environment with reinforcement learning methods which is computationally more efficient. Although these research showed cost-efficiency and good performance with reinforcement learning, analysis on effect of different RL methods is deficient considering the nature of human body motion. This research presents comparison between reinforcement learning with deterministic policy and stochastic policy in the lower limb exoskeleton control task. |
Enhancing Autonomous Ship Navigation: Integrating Sensor Reliability in Deep Reinforcement Learning (Saeyong Park)
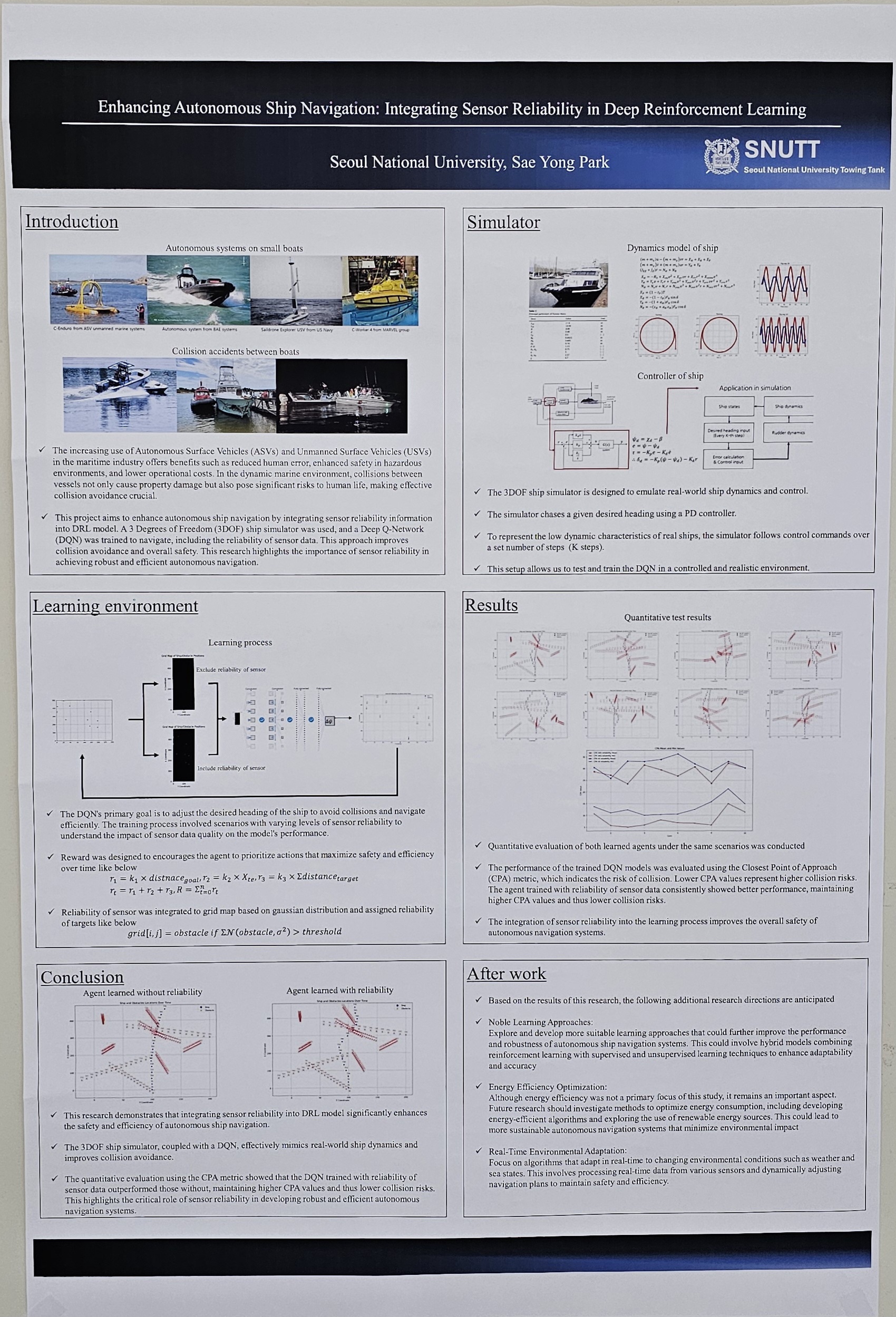
This study enhances collision avoidance in autonomous ship navigation by integrating sensor reliability into deep reinforcement learning (DRL). Traditional methods like A* and recent DRL techniques often neglect sensor data reliability, crucial for accurate obstacle detection. We utilize RADAR and AIS sensors, incorporating their reliability into a Deep Q-Network (DQN) model. Repetitive simulations show that this approach can improve decision-making and safety in dynamic maritime environments. Our findings offer a more robust solution for autonomous navigation, addressing sensor data uncertainties and advancing safer maritime operations. |

The Three-Dimensional Bin Packing Problem (3D-BPP) presents a significant challenge in combinatorial optimization, focusing on maximizing space utilization by arranging items within a bin. The online variant, where only a limited number of items are revealed for packing at a time, is extensively studied due to its relevance in logistics scenarios that require sequential decision-making without prior knowledge of future items. Recent advancements in Deep Reinforcement Learning (DRL) have demonstrated potential in improving packing strategies, and there has been a growing focus on enhancing spatial utilization by integrating reinforcement learning with the use of buffers. However, these approaches typically overlook the physical space limitations of buffers, instead imposing an arbitrary cap on the number of items accommodated. This paper introduces a novel approach that employs a reinforcement learning agent combined with Monte Carlo Tree Search (MCTS) to enhance bin packing efficiency by utilizing a fixed-size, realistic buffer to reorder items. We conducted performance comparison experiments to evaluate space utilization with and without a buffer, and across different buffer sizes. Our results demonstrate that the DRL agent significantly outperforms random sampling based on heuristic placements, markedly improving space utilization and increasing the number of items packed into the bin. Additionally, larger buffer sizes further enhance performance, underscoring the critical role of realistic buffer capacity in optimizing packing efficiency. These findings highlight the potential of advanced DRL techniques and the strategic use of realistic buffers in addressing complex bin packing problems and improving automation in logistics. |
Model Predictive Control based Residual Reinforcement Learning for Autonomous Racing in Simulation (Sungpyo Sagong)

This project proposes a model predictive control (MPC) based reinforcement learning (RL) algorithm for autonomous racing. Autonomous driving technology has seen significant advancements, with deep learning employed for detection and mapping to decision-making and control processes. Autonomous racing, a particularly challenging task within autonomous driving, involves complexities such as tire slip with nonlinear dynamic friction analysis. This project utilizes RL to control racing cars within a complex environment. RL can optimize control inputs through real data without dynamics, enabling strategic development during races, but convergence is slow and needs a lot of data to achieve good performance. MPC which follows a precomputed reference path offers proper control inputs even without any learning but actions are not optimal and hard to improve. This project proposes and tests several MPC combined RL methods, and suggests the residual RL method which uses MPC as nominal input and RL as residual adjustment by linear summation of control input to accelerate the learning process by minimizing unnecessary exploration. The integration of MPC and RL is evaluated in the racing simulator and outperforms each separate method for performance and convergence speed. |
Environment-Constrained Robot Navigation Using Deep Reinforcement Learning for Crowded Scenarios (Yeongin Yoon)
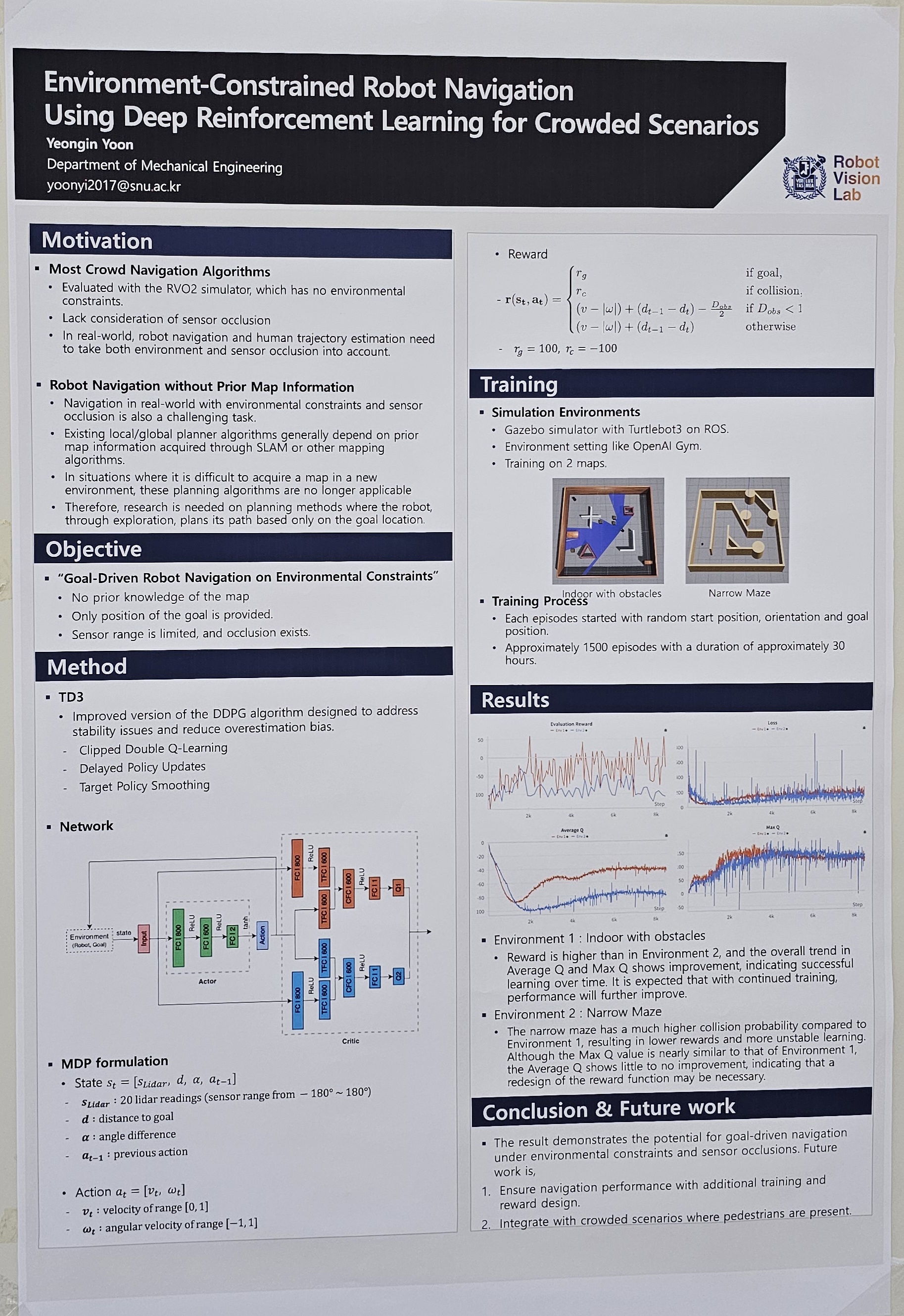
Recent research on robot navigation in complex crowded environments has been steadily progressing. Recent efforts have gone beyond focusing solely on the robot, emphasizing interactions between robots and humans during navigation. However, most of these recent studies consider the relationships between humans and robots and between humans, but do not take environmental constraints into account. Learning with these environmental constraints can provide valuable cues for not only the robot's path planning but also for predicting human paths. Furthermore, many studies assume that all obstacles within the robot's sensing range are fully observable, without considering sensor occlusion. In this study, we address these limitations by using a Gazebo and Gym integrated environment (Gazebo Gym) to construct scenarios with environmental constraints, and apply deep reinforcement learning to solve the navigation task in such environments. Our experiments demonstrate that successful robot navigation can be achieved in simulation environments that include environmental constraints. These findings suggest potential directions for future research, where strategies for navigation can be developed by leveraging human intentions and environmental cues. |

Path planning is a fundamental component in the field of mobile robotics, underpinning the efficiency and effectiveness of autonomous systems. The Rapidly-Exploring Random Tree (RRT) and its enhanced variant, RRT*, are pivotal sampling-based algorithms in global path planning, widely adopted for their adaptability and robustness across diverse robotic applications. Despite their popularity, these algorithms often face efficiency challenges due to the excessive sampling of non-contributory nodes, which increases computational demands and prolongs inference times. Addressing this inefficiency necessitates a refined approach to the sampling process, focusing on selecting points within significant areas. This study introduces an innovative solution through the development of a reinforcement learning-based intelligent agent designed to optimize this sampling process. The environment for training the agent was specifically developed to enhance node sampling decisions within the RRT* framework. By integrating strategies from prior research, this agent leverages occupancy maps, current nodes in the RRT* tree, and specific start and goal positions to dynamically generate optimal sampling points. Comprehensive evaluations demonstrate that the performance of the trained agent surpasses that of the conventional RRT* and its variants in terms of sampling efficiency. This approach aims to substantially enhance path efficiency and reduce computational overhead, thus improving overall system performance in real-time applications. This research is anticipated to set a precedent for the integration of advanced machine learning techniques in path planning algorithms. |

Unmanned Aerial Vehicles (UAVs) have become increasingly significant due to their versatility and capability to perform operations beyond human reach. Among UAVs, quadrotors stand out due to their Vertical Take-Off and Landing (VTOL) capabilities and agility, making them ideal for applications such as surveillance, disaster management, and environmental monitoring. However, controlling quadrotors is challenging due to their nonlinear dynamics, coupling effects, and susceptibility to disturbances such as model uncertainties and wind gusts. Traditional control methods, including PID and LQR controllers, often require manual tuning and may not guarantee optimal performance across all operating conditions. This research proposes a novel approach that integrates Deep Reinforcement Learning (DRL) with Nonlinear Dynamic Inversion (NDI) to automate the gain tuning process, ensuring robust and stable control of quadrotors. By incorporating Lyapunov stability criteria into the reward function, the proposed method aims to enhance both the performance and stability of the control system. Soft Actor-Critic (SAC) is employed to optimize the control gains dynamically, leveraging its efficiency and stability. The study formulates the quadrotor dynamics, details the NDI controller design, and integrates Lyapunov-based rewards to guide the learning process. The effectiveness of the proposed method is evaluated through comprehensive simulations, comparing manually tuned NDI controllers with those optimized using SAC. The results demonstrate that the DRL-based approach can significantly improve the robustness and optimality of quadrotor control systems. |
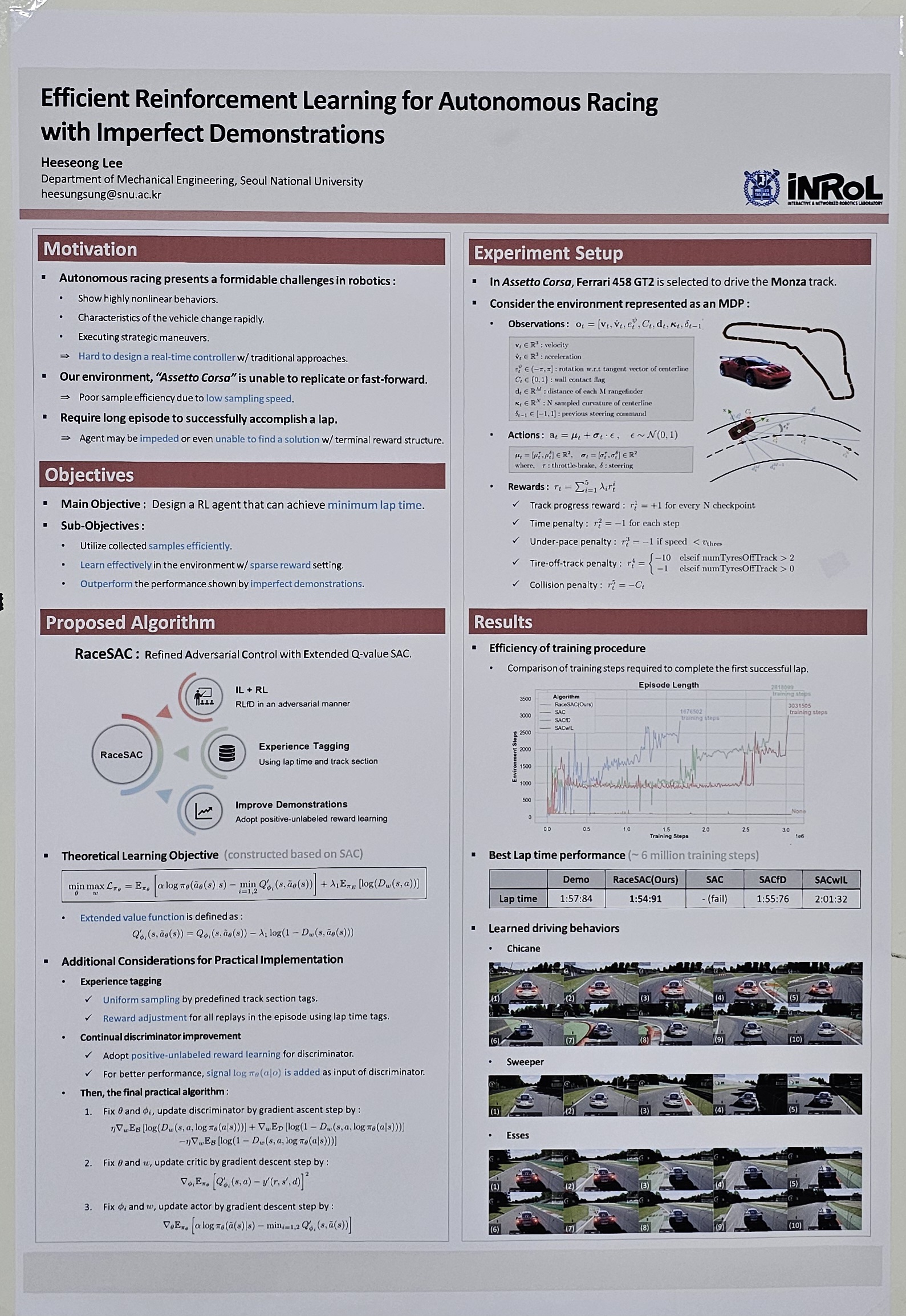
Autonomous car racing presents formidable challenges in robotics, requiring controllers capable of managing highly nonlinear behaviors and extreme action limits. Recent advancements have shown that Reinforcement Learning (RL)-based end-to-end systems achieve promising results in autonomous racing. Nevertheless, these systems often struggle with exploration inefficiencies in sparse reward environments. Learning from Demonstrations (LfD) has emerged as a solution by utilizing expert demonstrations to guide learning. In this work, we propose a novel approach, RaceSAC, which effectively utilizes imperfect demonstrations to guide exploration by enforcing occupancy measure matching. Our method builds on the Soft Actor-Critic (SAC) framework and employs an adversarial approach by modifying the value function. We conduct experiments in Assetto Corsa, a renowned simulator known for its realistic modeling. Evaluation results demonstrate that our method surpasses existing approaches in terms of learning speed and final lap time performance, and even outperforms the provided demonstrations, while retaining the benefits of off-policy, actor-critic methods. Furthermore, the driving behavior shown by our model is very similar to the behavior shown by expert human drivers. |
Leveraging Equivariant Representations of 3D Point Clouds for SO(3)-Equivariant 6-DoF Grasp Pose Generation (Byeongdo Lim)

Achieving equivariance in robot learning tasks, particularly in the generation of grasp poses for various objects, has garnered significant attention due to its advantages such as data efficiency, generalization, and robustness. In this paper, we propose GraspECMF (Equivariant Conditional Manifold FLows for grasping), a novel method for SO(3)-equivariant grasp pose generation. Our method leverages SO(3)-equivariant representations of objects to learn the invariant distribution of grasp poses conditioned on the objects. Experimental validation demonstrates that our method outperforms existing methods, showcasing enhanced accuracy in grasp pose distribution learning and resulting in a higher grasp success rate. |
Trajectory Tracking Control for Autonomous Racing Based on Tube-MPC and LSTM-DDPG Algorithm (Myeonggeun Jeon)
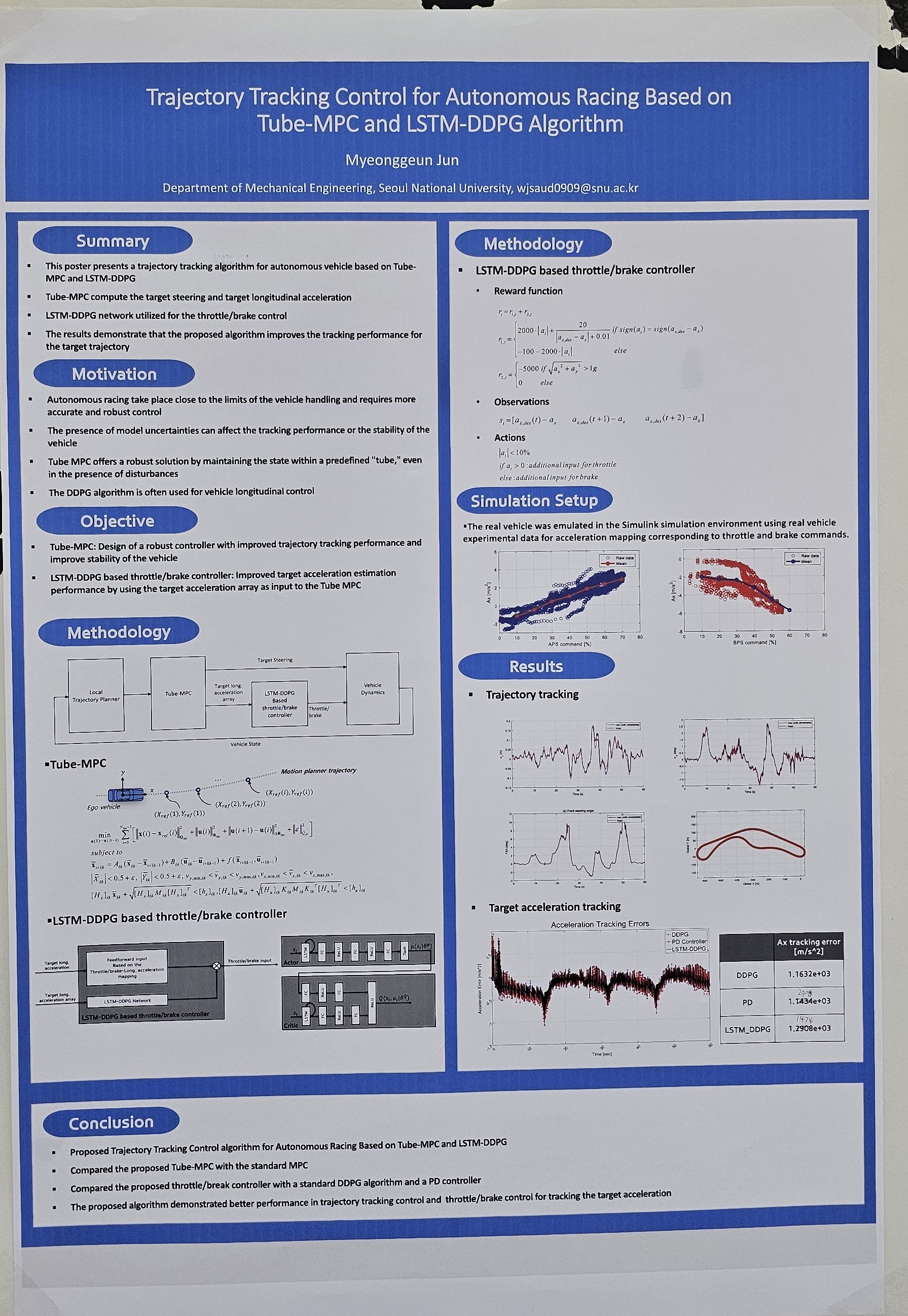
This paper presents a trajectory tracking control system for autonomous racing based on a Tube Model Predictive Control (TMPC) and a Deep Deterministic Policy Gradient with Long Short-Term Memory (LSTM-DDPG) algorithm. The proposed system is designed to enhance the tracking accuracy and stability of autonomous racing vehicles. The Tube-MPC calculates the target accelerations and steering angles, providing control inputs that ensure robust performance against disturbances. The LSTM-DDPG algorithm then utilizes these inputs to control throttle and brake, compensating for input delays by incorporating historical target accelerations, control inputs, and actual accelerations. To emulate real vehicle dynamics, the longitudinal modeling of the vehicle is achieved by regressing longitudinal acceleration data based on throttle and brake input percentages. The system applies feedforward throttle and brake inputs based on this mapping, and the DDPG-LSTM framework introduces additional feedforward inputs to compensate for delays. The reward function is structured to provide higher rewards for minimizing the difference between target and actual accelerations and includes penalties for surpassing handling limits to prevent the tire saturation of the vehicle. Simulation results from Matlab/Simulink demonstrate that the proposed system effectively reduces tracking errors, enhances vehicle stability, and maintains robust control under various racing conditions. Compared to nominal MPC, the Tube-MPC significantly reduces tracking errors and improves stability. Additionally, the LSTM-DDPG based throttle/brake controller enhances acceleration tracking performance compared to a PD controller. |
3. RL for AI Systems
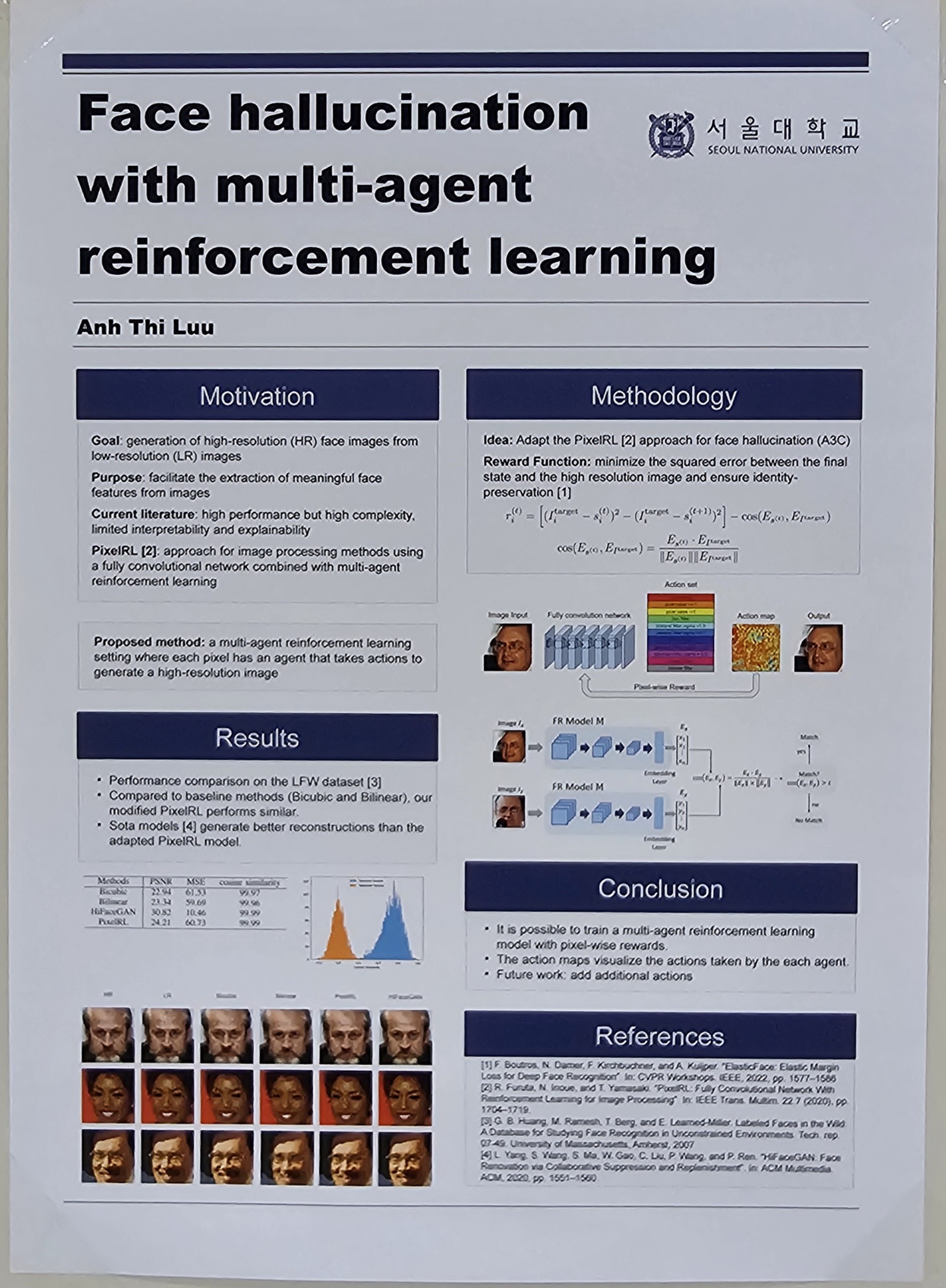
Face hallucination methods address the problem of generating high-resolution face images from low-resolution images. While state-of-the-art face hallucination techniques already achieve high performance, the complexity of the models is very high, resulting in the need for large training datasets, long training times, and complex models. This limits the interpretability, which lowers trust in such models. In this paper, we want to tackle the problem of face hallucination using reinforcement learning with pixel-wise rewards. More specifically, we propose a multi-agent reinforcement learning setting where each pixel has an agent that takes actions to change the pixel. Further, we use a learning method that considers the future states of the pixel as well as those of neighboring pixels. This work should enhance the explainability and interpretability of face hallucination networks by visualizing the actions taken by the agents. Our experimental results demonstrate that the proposed method achieves comparable performance to baseline methods. |

This work aims to generate realistic and contextually accurate human motions by leveraging vision-based datasets and text embeddings. Existing methods often overlook the complexity of real-world interactions, focusing on isolated actions without considering surrounding objects and spatial dynamics. Our approach aims to address these limitations by incorporating object displacement and spatial layouts into the synthesis process. By extending Adversarial Motion Priors (AMP) and integrating text embeddings, we seek to enhance the fidelity of character motions in diverse indoor scenarios. Our work is evaluated based on success rates, execution times, penetration rates, and volumetric Intersection over Unions (IoUs) to measure interaction accuracy and object interference. |
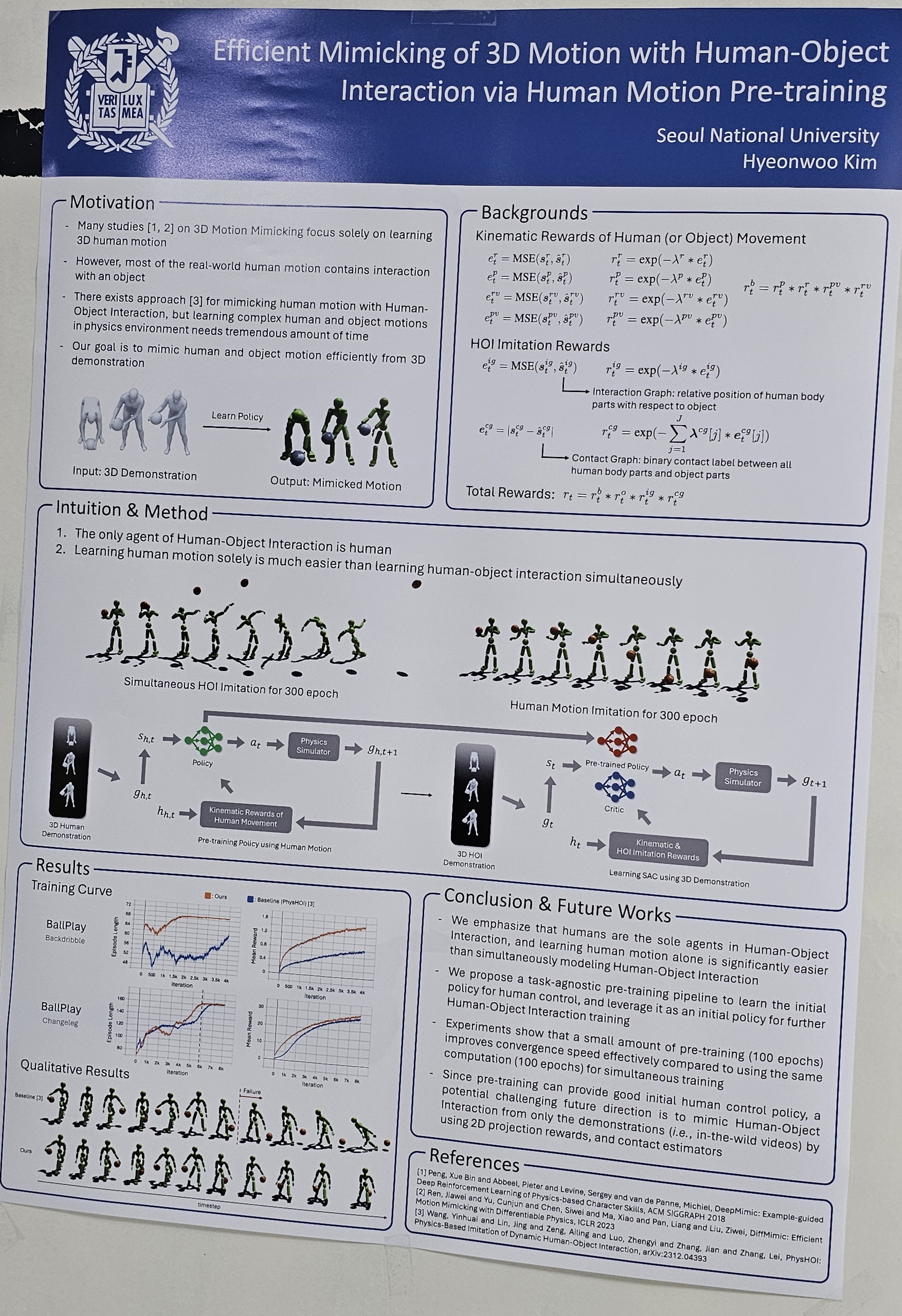
Motion mimicking, which learns the control signal policy required to reproduce both the overall trajectory and the manipulation of specific body parts, has a wide range of applications in physics-based environments such as games, VR/AR content. However, many mimicking studies relies on high quality 3D demonstrations, which is expensive. In this paper, we mimic human-object interaction (HOI) using 2D demonstrations (i.e, videos) instead of 3D demonstrations. Given videos, we first synthesize 3D demonstrations of human motion using an off-the-shelf human pose and shape estimator, and learn initial policy for human state. Then, we learn a residual value function and actions based on the human-object state to ultimately mimic the HOI. As there are no demonstrations for 3D objects, we propose a new reward based on 2D projections. To evaluate our 2-stage mimicking, we conducted an experiments with baselines using the BallPlay dataset. |
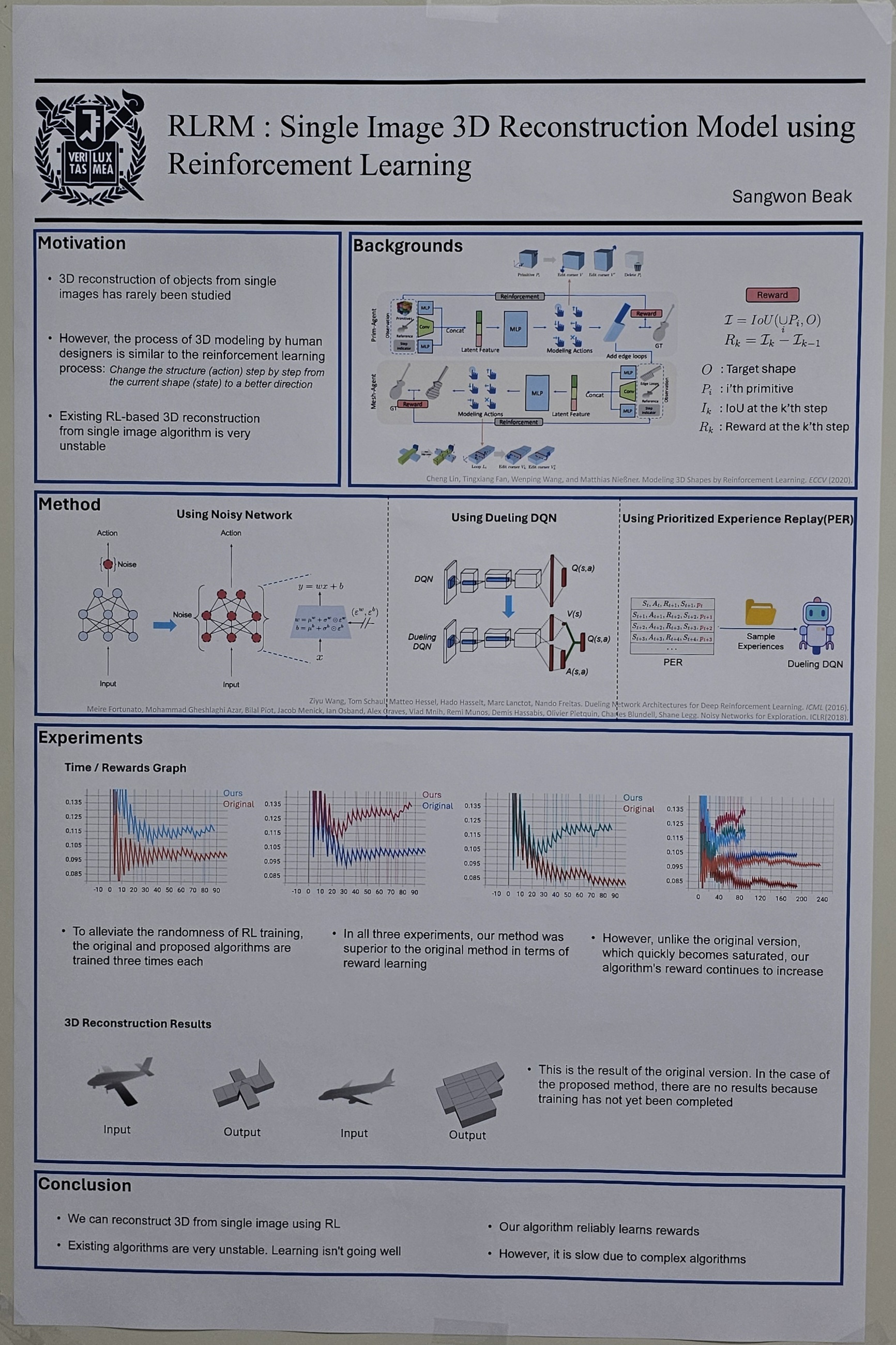
We explore how to perform single image 3D reconstruction with reinforcement learning. Reinforcement learning-based single image 3D reconstruction tasks have rarely been explored, and the results shown by existing works are very naive. In particular, existing studies only learn at low resolution due to the three-dimensional state-action space where the resolution increases by the cube. Following the approach of previous work, we divide it into a shape abstraction step that captures the rough shape and a mesh editing step that captures details. However, we explore the state-action space faster and more efficiently, learning efficiently at larger resolutions and producing much better quality results. |
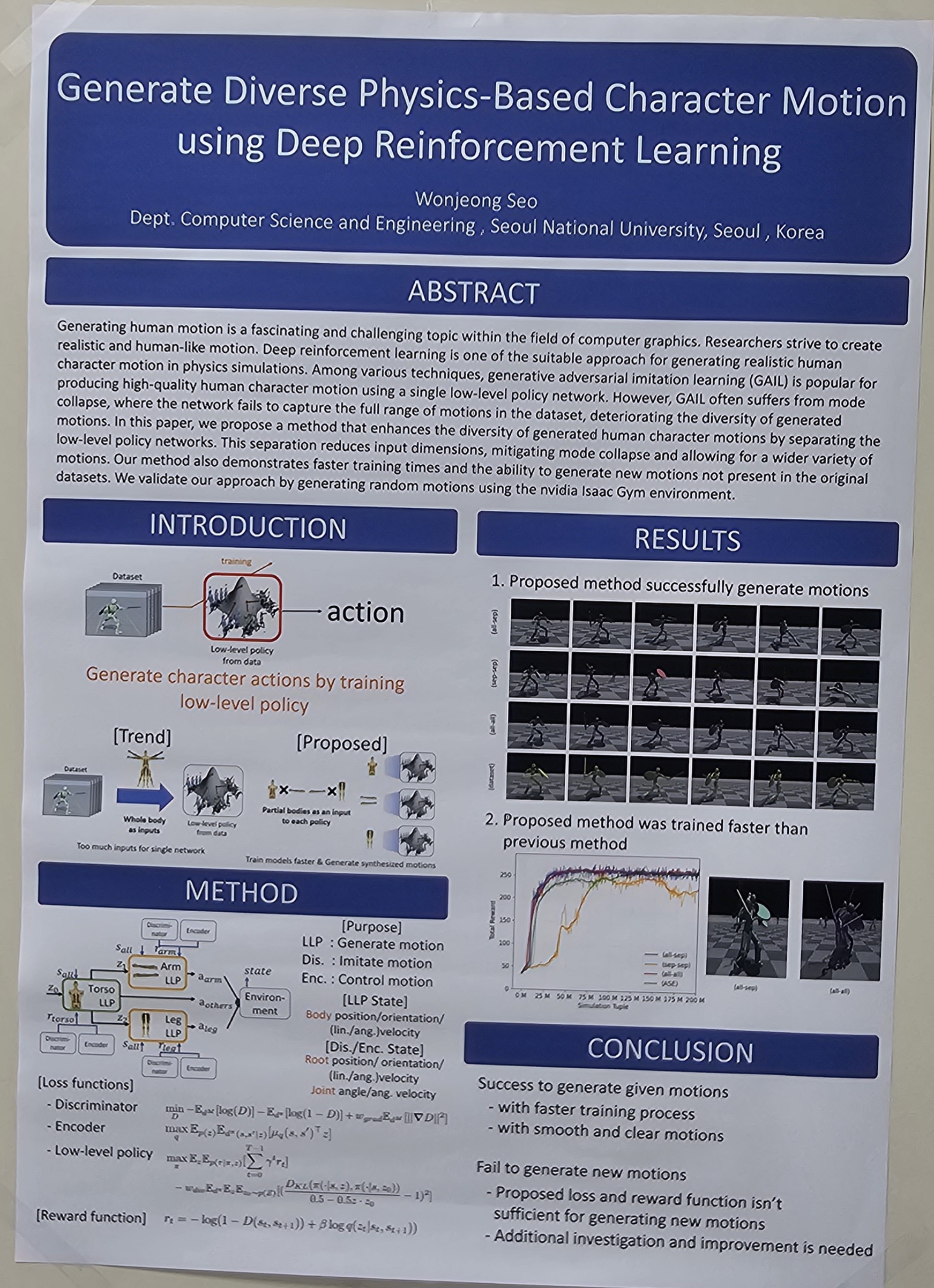
Generating human motion is a fascinating and challenging topic within the field of computer graphics. Researchers strive to create realistic and human-like motion. Deep reinforcement learning is one of the suitable approach for generating realistic human character motion in physics simulations. Among various techniques, generative adversarial imitation learning (GAIL) is popular for producing high-quality human character motion using a single low-level policy network. However, GAIL often suffers from mode collapse, where the network fails to capture the full range of motions in the dataset, deteriorating the diversity of generated motions. In this paper, we propose a method that enhances the diversity of generated human character motions by separating the low-level policy networks. This separation reduces input dimensions, mitigating mode collapse and allowing for a wider variety of motions. Our method also demonstrates faster training times and the ability to generate new motions not present in the original datasets. We validate our approach by generating random motions using the nvidia Isaac Gym environment. |

In this study, we address the limitations of existing graph neural network (GNN) models in predicting links within graph datasets, particularly in domains where structural information is crucial. Traditional heuristic methods for link prediction often fail to capture complex graph structures, while GNNs, despite their advancements, struggle with tasks requiring nuanced structural comprehension. We propose a novel approach utilizing Deep Reinforcement Learning (Deep RL) with Deep Q-Networks (DQNs) to enhance link prediction capabilities in graphs. Our method involves formulating the link prediction task as a reinforcement learning problem, where the agent learns to predict the existence of edges based on state observations that include multi-hop neighborhood information. The proposed model is validated on datasets such as the Power Network, C.Ele Benchmark, and YST, where GNNs have shown suboptimal performance. Through rigorous comparative experiments, we aim to demonstrate that our Deep RL-based approach can effectively overcome the structural limitations of existing methods, offering improved performance in predicting missing links in complex networks. |

We present a versatile latent representation that enables physically simulated character to efficiently utilize motion priors. To build a powerful motion embedding that is shared across multiple tasks, the physics controller should employ rich latent space that is easily explored and capable of generating high-quality motion. We propose integrating continuous and discrete latent representations to build a versatile motion prior that can be adapted to a wide range of challenging control tasks. Specifically, we build a discrete latent model to capture distinctive posterior distribution without collapse, and simultaneously augment the sampled vector with the continuous residuals to generate high-quality, smooth motion without jittering. We further incorporate Residual Vector Quantization, which not only maximizes the capacity of the discrete motion prior, but also efficiently abstracts the action space during the task learning phase. We demonstrate that our agent can produce diverse yet smooth motions simply by traversing the learned motion prior through unconditional motion generation. Furthermore, our model robustly satisfies sparse goal conditions with highly expressive natural motions, including head-mounted device tracking and motion in-betweening at irregular intervals, which could not be achieved with existing latent representations. |

The performance of representing long and phased instructions into linear temporal logic (LTL) has been approved recently. When giving command to the RL agents, it is hard to make them understand the original purpose if the command is long and complicated. On that point the LTL designed instructions have advantages by specifying time order in the command using the temporal operators. Given the set of propositions, it was proved that agents can learn the optimal policies of the formulas that are constructed by the elements of the set. However if new propositions are given, the generalization performance is not guaranteed. Some works are discussing about this problems. My proposed learning approach uses the similarity of formulas in embedding space made by the Graph Neural Networks (GNNs) . Specifically, proving that the preservation of the similarity from raw base space to the embedding space enables the agents to better utilize environmental characteristics is the main purpose. |

A berth is a location in a port where a vessel stays while its containers are loaded or unloaded. Because it is the starting point for all port operations, efficient allocation of vessels to berths is very important for the port. Due to uncertainties of vessel arrival times, berth allocation based on deterministic information can not be implemented in real-world. Therefore, many previous studies have proposed efficient algorithms to solve the dynamic berth allocation problems (DBAPs). However, most of them proposed two-stage stochastic optimization algorithms or rolling horizon heuristics, which cannot immediately provide new schedules when a delay in the arrival of a vessel is observed. To fill this research gap, we propose a hierarchical reinforcement learning (HRL) algorithm to compute the recovery schedule. In the proposed algorithm, an upper-level agent determines whether or not to assign the currently waiting vessels to the berths. When the upper-level agent approves the assignment, a lower-level agent selects a dispatching rule and assigns each vessel to a berth with the rule. We conduct numerical experiments to evaluate the proposed HRL algorithm using the physical model of Busan Port Terminal and its real data. |
Road Graph Attention Model: Solving Pickup and Delivery Problem on Road Graph Environment (Geunje Cheon)
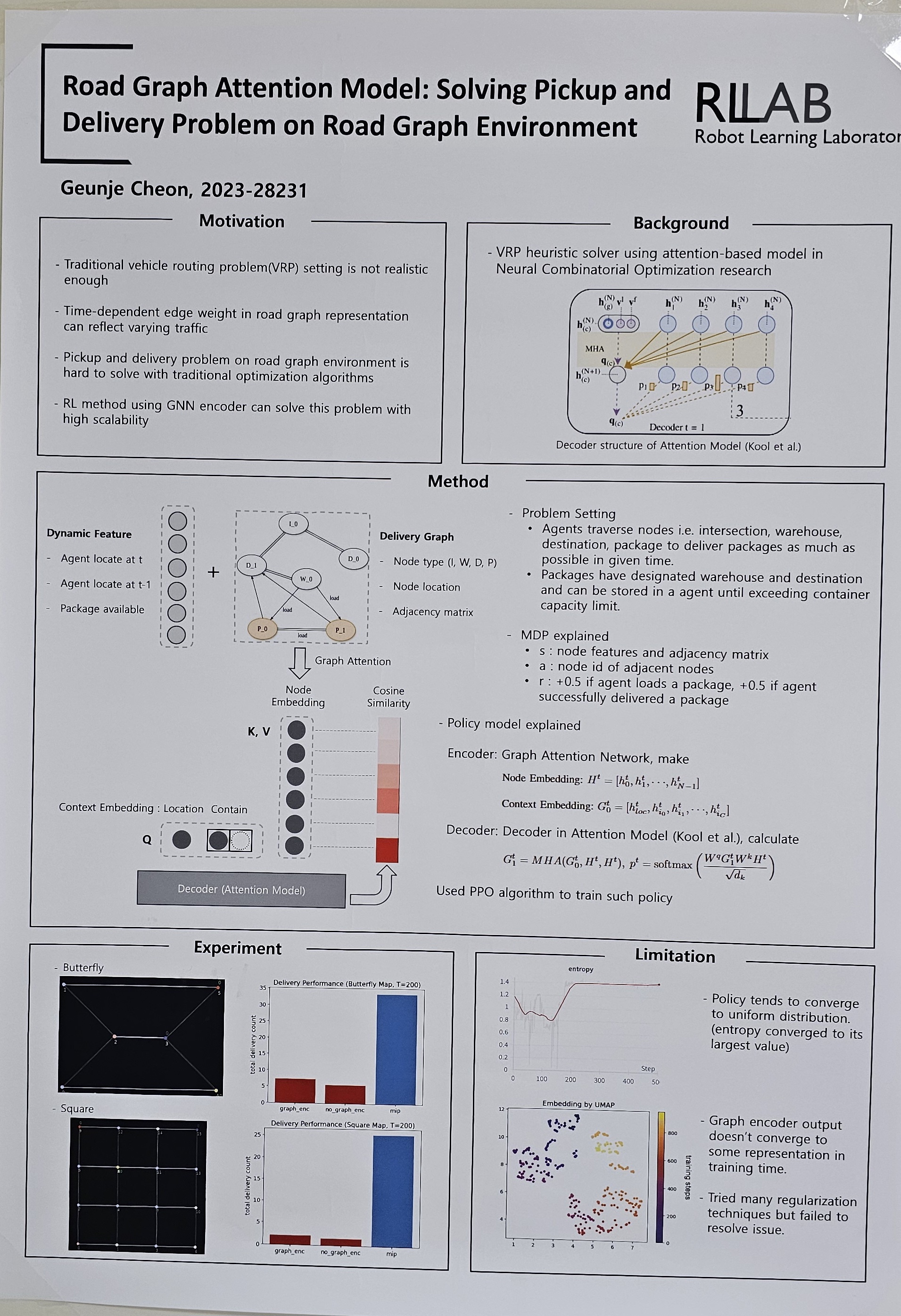
We propose a novel reinforcement learning (RL) approach to optimize multi-vehicle pickup and delivery schedules, addressing the limitations of traditional Vehicle Routing Problem (VRP) solutions that assume fixed travel costs. Our approach incorporates dynamic traffic conditions within a road graph environment, where nodes represent intersections, warehouses, and delivery destinations, and edges represent roads with variable travel times predicted by a traffic model. Using graph neural networks (GNNs) to encode node and edge features, we train RL agents with Proximal Policy Optimization (PPO). These agents navigate the road graph, load and unload packages, and aim to minimize travel time while respecting capacity constraints. We compare performance of our RL approach with a mixed integer programming solver. |
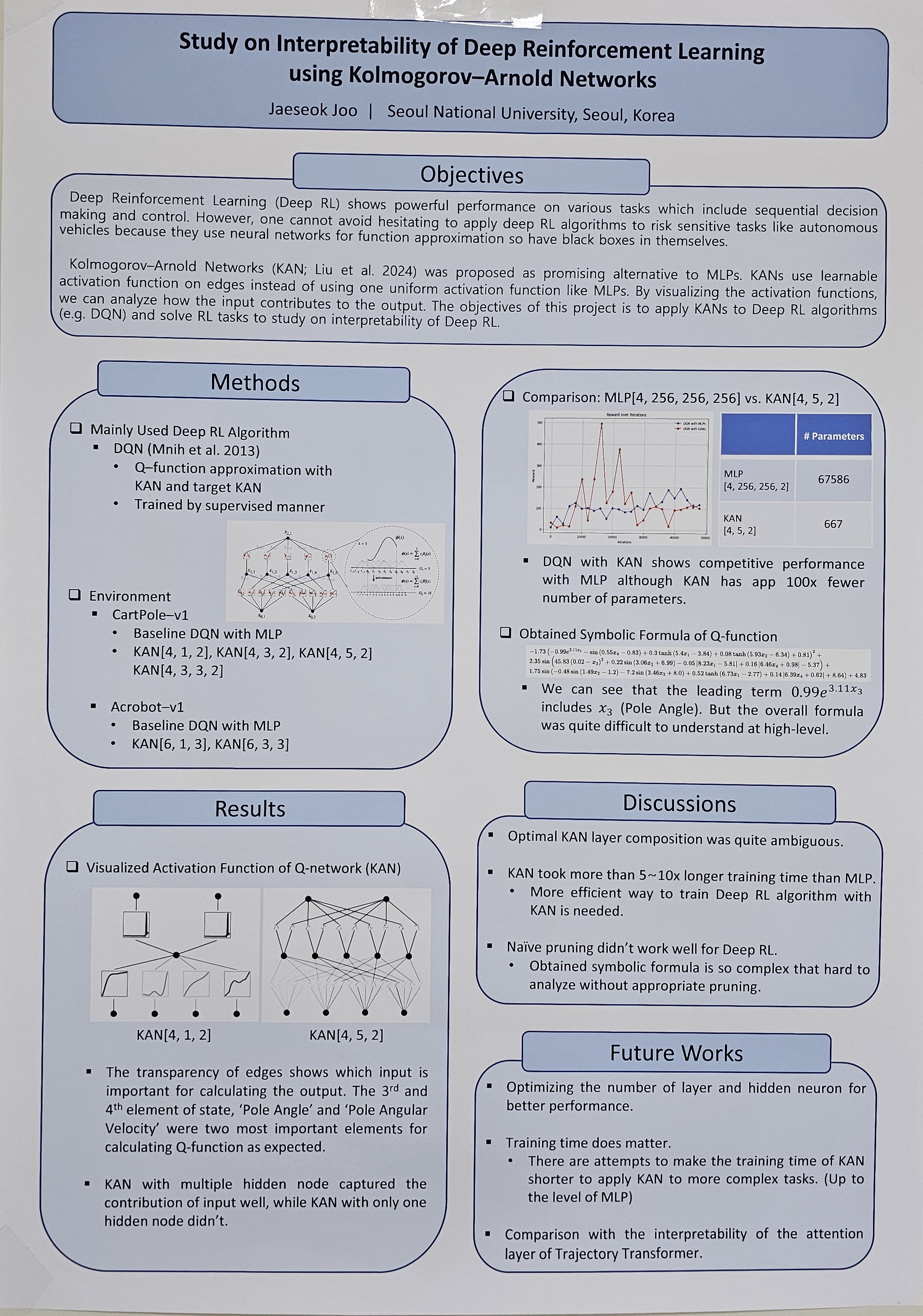
Reinforcement Learning (RL) is a machine learning methodology which shows performance for sequential decision making and control. There are a lot of attempts to apply reinforcement learning to various tasks related to decision making or control like robotics, surgery and trading. However, Deep Reinforcement Learning (DRL), which exploits neural networks for approximation cannot avoid interpretability issues. It makes ones hesitate applying deep reinforcement learning to surgery or trading which involves critical risks. Kolmogorov-Arnold Networks (KAN; Liu et al. 2024), which is based on Kolmogorov-Arnold Representation Theorem, serves as an alternative to MLP with a learnable activation function. By visualizing the learned activation function, we can analyze how inputs contribute to outputs, providing interpretability to the learned model. In this project, I am trying to apply KAN to various RL algorithms and tasks to explore the direction for interpretable RL. |

This paper presents a technical description of a reinforcement learning control method for systems with uncertainties, based on the observability of nonlinear systems. This paper introduces the problems to be solved using Soft-actor critic and discusses the minimum conditions of the input to produce the desired performance of reinforcement learning. Specifically, it focuses on enhancing reinforcement learning performance through conditions that ensure the observability of system states and internal parameters. Lastly, we build on the previous discussions to detail the design process of inputs for reinforcement learning, utilizing the observability of nonlinear systems, and show the effectiveness of proposed methods through experimental results. |

This project suggests a concept of 'anti-agent' for memory-based Reinforcement Learning approches. For most RL methodologies, it is natural to collect trajectories from environments and use these data to make agents learn optimal policies. In early stages of learning, agents will fail more often rather than succeed. This will enable them to learn which actions to avoid to get more rewards at the end. Their polices will get updated to result in actions and transitions that give them more rewards. Memory will also be filled with such data In the later part of reinforcement learning. Thus agents won’t observe bad actions that teach them what not to do, making them frail to perturbations near good trajectories. From this point, the idea of anti-agent arises. Actual agents who learn optimal policies are not bothered at all. Instead, a new agent, anti-agent can be introduced, who performs opposite actions to the original agents. Then policy will be updated with trajectories from both normal agent and anti-agent with predetermined ratio. Validity of anti agent is first tested on rather simple tasks in gymnasium (Acrobot, CartPole) and more difficult tasks. |