
Project
Information
- Date: 2021/06/16 (Wednesday)
- Time: 11:00AM - 1:00PM
Entropy Regularization, Network Architecture Search
- Conservative Q-Learning with Gamma-Model Based Density Estimation (Mingyu Park)
- Distributional Tsallis Actor-Critic (Jaeyeon Jeong)
- Mutual Information State Intrinsic Control (MUSIC) improvements with Sparse Tsallis Entropy Regularization (Jongkook Kim)
- Deep Reinforcement Learning for Network Architecture Search (Jaehyoung Yoo)
- Meta-Learning with Deep Elastic Networks (Hongjung Lee)
Robots (1): Exploration, Skill Chaining, Hierarchical Control, Standoff Tracking
- Autonomous Robot Exploration with Deep Reinforcement Learning (Dabin Kim)
- Best Action as Label: Pseudo Labeled DQN With Best Action Classifier (Taehoon Kim)
- Monte-Carlo Skill Chaining from Fragmented Demonstrations (Minjae Kang)
- Learning multiple gaits of quadruped robot using hierarchical reinforcement learning (Yunho Kim)
- Standoff Tracking Using Vector Fields Guidance with Reinforcement Learning (Hyeong-gwan Kang)
Robots (2): Metal-RL, Model-based, Gaussian Process Regression, Multi-Agent, Sim2Real
- MPC-assisted Meta-Reinforcement Learning for Safe Navigation (Astghik Hakobyan)
- Neural Gaussian Random Path Policy (Jeongwoo Oh)
- Influence based Reward for Communicative Multi-Agent Reinforcement Learning (Minyoung Hwang)
- Robust Control with Grounded Action Transformation using Gaussian Blurring (Sumin Lee)
Computer Vision / Vision-based robotics
- Affine Transformer Defense Proposal for Adversarial Attack by using Reinforcement Learning (Hyungjin Kim)
- Learning to Skip Empty Feature Maps (Nghia Tuan Nguyen)
- Policy Gradient Attack Against Out-of-Distribution Detectors (Sangwoong Yoon)
- Analyzing Keypoint Detection Methods with Q-Learning Approach (Howoong Jun)
- Image Goal Navigation Using Keypoint Detection and Map Prediction (Jaeseok Heo)
Applications
- A Reinforcement Learning Approach for In-Memory Database Cache Replacement Policy (Taehun Kang)
- Automated tuning of semi-conductor quantum dot devices (Kyunghoon Jung)
- End-to-end Waveform Generation for Improvising a Musical Instrument (Jinwoo Lee)
- Miniature Wargame "Warhammer 40,000" environment for deep reinforcement learning (Flin Hoepflinger)
- Risk-aware Trading Agent using Reinforcement Learning (Jungsub Rhim)
A Reinforcement Learning Approach for In-Memory Database Cache Replacement Policy (Taehun Kang)

Cache replacement policy of the in-memory database is critical to its performance. In this work, we propose a reinforcement learning-based approach for the cache replacement policy of the in-memory database. |
Affine Transformer Defense Proposal for Adversarial Attack by using Reinforcement Learning (Hyungjin Kim)
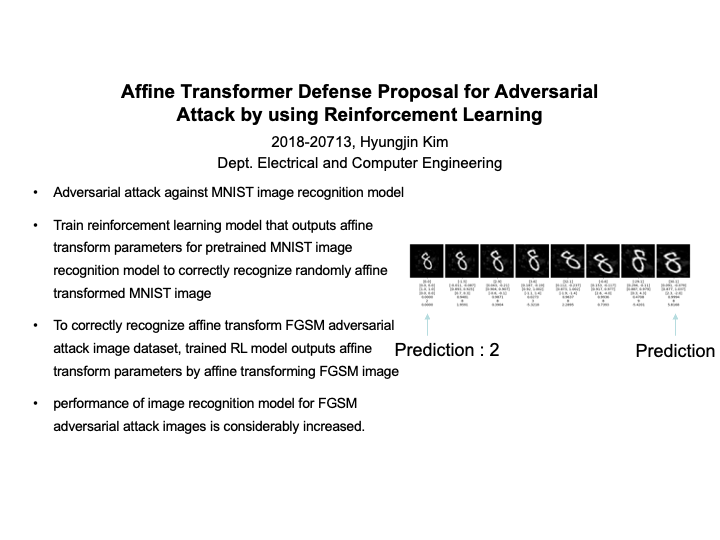
Image recognition performance through deep learning using a neural network has drastically increased. However, the neural network has the disadvantage of being helpless when subjected to an adversarial attack. We present a way to defend against the adversarial attack by transforming the image of the adversarial attack image through affine transformer. The Fast Gradient Sign Method was used to create an adversarial attack on image recognition model that pre-trained MNIST dataset. We use reinforcement learning to gain affine transformer parameters needed to transform random affine transformed MNIST dataset for pre-trained image recognition model to correctly recognize input image data. Using learned reinforcement learning model, FGSM adversarial attack images were affine transformed several steps to be well recognized by image recognition model and performance of image recognition model for FGSM adversarial attack images is considerably increased. |
Analyzing Keypoint Detection Methods with Q-Learning Approach (Howoong Jun)

In this work, a new method for analyzing ap-propriate keypoint detection model from a given image isproposed. Robust keypoint detection in images with diverseconditions, such as illumination and viewpoint, is a major issuefor visual simultaneous localization and mapping (SLAM), placerecognition, and computer vision field. To handle this issue,the proposed method named adaptive model selecting systemencodes the image and selects the best model to get sufficientnumber of keypoints. The method is trained with q-learning.Also, a new approach for detecting keypoints named Event-PointNet which focuses on the images with low illuminationis proposed. In the proposed selecting system, there are fourcandidates for the selection: scale-invariant feature transform(SIFT), oriented FAST and rotated BRIEF (ORB), SuperPoint,and the proposed EventPointNet. The overall purpose of thiswork is to analyze each keypoint detectors and prove that theproposed EventPointNet is frequently selected from the adaptivemodel selecting system. |
Automated tuning of semi-conductor quantum dot devices (Kyunghoon Jung)
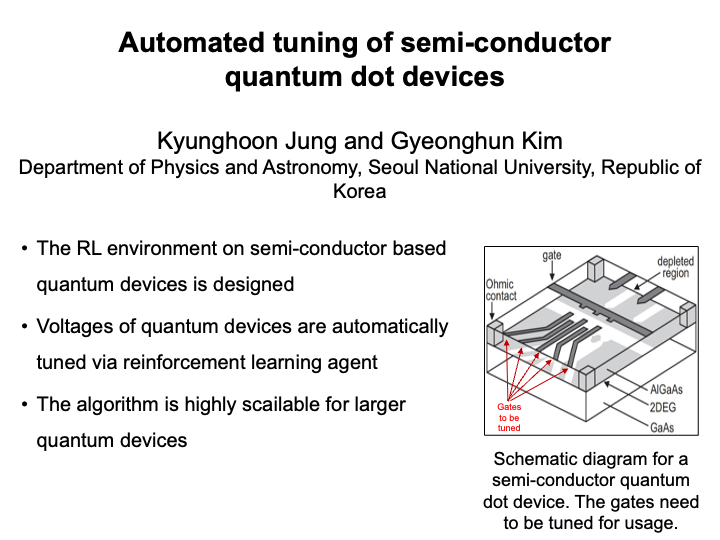
Semiconductor-based quantum dot device for realizing quantum computer systems keeps drawing attention due to its advantages such as scalability via semiconductor fabrication technology, long coherence time, and high degrees of tunable parameters. However, tuning procedures of the devices for reliable operation is difficult to be scaled up towards larger integrated systems because the process has been manually done by examining the stability diagram of two gates. Many researchers try to design automated techniques for tuning the quantum devices. However, most of them apply the algorithm in restricted ways, such as only using it for state recognition or step by step tuning with different methods. In this work, we use deep reinforcement learning to fully automate the tuning of the multiple qubits. As the starting point, we restrict the environment with relatively easier settings and train the agent to find an optimal path in the parameter space of tuning. |
Autonomous Robot Exploration with Deep Reinforcement Learning (Dabin Kim)
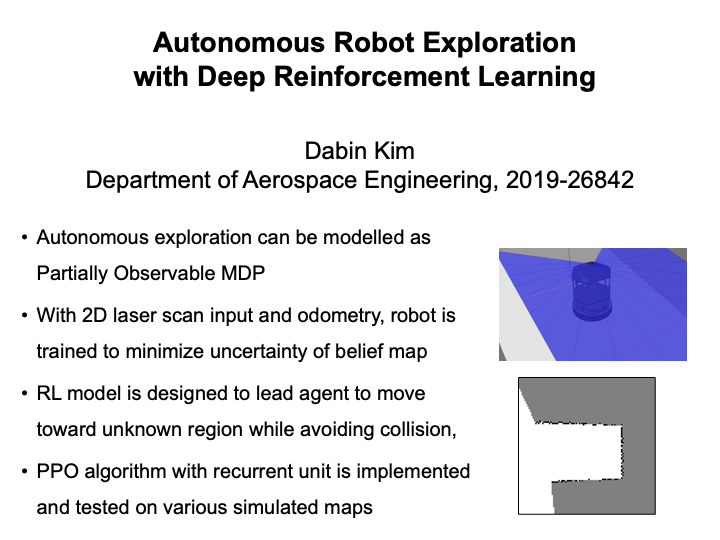
Autonomous exploration is one widely studied application of robotics, where the robot tries to search priorly unknown environment with its mounted sensor. Among various interesting issues of autonomous exploration, one of the core algorithm required is sequential decision-making of robot's action. At each time step, robot has to decide the motion to maximize new information about the environment based on action and observation history. Also, since robot does not have full information about the state and observation, autonomous exploration problem can be modelled as POMDP. In this project, we applied deep reinforcement learning (DRL) method to autnomous exploration problem. Based on 2d laser scanner input and odometry of the robot, DRL agent is trained to infer the best next motion. We implemented PPO as DRL algorithm, and added recurrent unit to learn on partially observable domain. The trained agent is validated on various simulated maps. |
Best Action as Label : Pseudo Labeled DQN With Best Action Classifier (Taehoon Kim)

Since DQN [1] has proposed, deep learning techniques have shown remarkable performances in reinforcement learning problems. However, despite their remarkable performances, in some areas they have shown the problem of instability in the learning process. In this paper, we propose a new method for stabilizing the learning process of Q- network. Similar to Dueling DQN [2], we achieve our goal by disentangling the role of the Q-Network by giving predicted best action for the state so that it can focus on predicting the Q-value for best action only.
[1] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
[2] Z.Wang,T.Schaul,M.Hessel,H.Hasselt,M.Lanctot,andN.Freitas, N. “ Dueling network architectures for deep reinforcement learning,” In International conference on machine learning, pp. 1995-2003, 2016
|
Conservative Q-Learning with Gamma-Model Based Density Estimation (Mingyu Park)
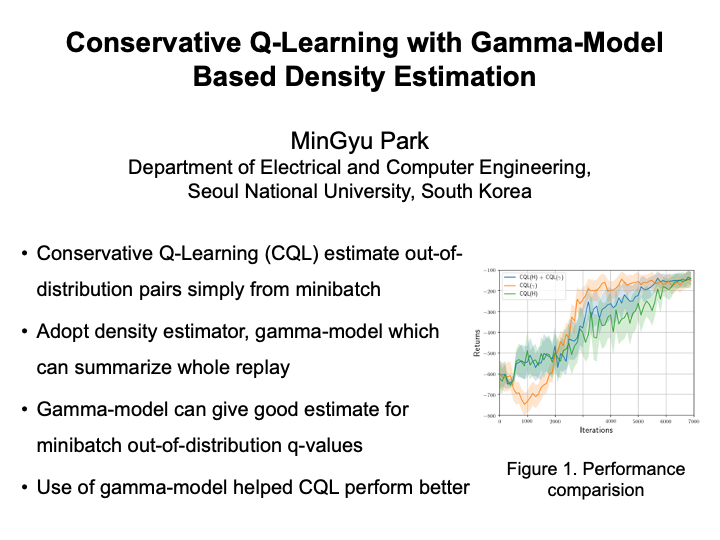
Conservative Q-learning is one of the most successful approaches to solve challenging offline reinforcement learning problems. However, adversarially attacking out-of-distribution state-action pairs has potential disadvantages; first, out-of-distribution is be measured within minibatch in practice, rather than via whole offline dataset. This can attack high q-values, thus rewarding state-action pairs that are present in offline dataset, but not in minibatch. Second, this error is further propagated by bootstrapping, so Q-function can be highly errornous. In our work, we suggest the use of gamma-models which can summarize whole offline dataset distribution in the whole offline dataset effectively via dynamic programming along with reward estimator that is simply learned via supervised learning. Gamma-model and reward estimator help estimate more correct Q-values from out-of-distribution state-action pairs, rather than adversarially attacking ODD actions. |
Deep Reinforcement Learning for Network Architecture Search (Jaehyoung Yoo)

Neural architecture search (NAS) has achieved great success in automating the human labor of finding a high-performance network. Although NAS has appeared recently, numerous approaches have been proposed to find higher-fidelity networks with lower search costs. While there have been many approaches based on deep reinforcement learning, most works are now dominated by evolutionary algorithms, Bayesian optimization, and more recent gradient-based methods. In this paper, we revisit the deep reinforcement learning for the neural architecture search problem, seeking ways to outperform other state-of-the-art methods in the NAS-Bench-101 benchmark. We propose a sequential action sampling framework based on the value-based Deep Q-Learning (DQN) with search configuration from NAS-Bench-101, where each action means a connection between operation layers in a given cell. With fixed operations in a given cell, we were able to outperform all the other methods by adopting the replay buffer, soft updates to the target network, and epsilon-greedy exploration scheme coming from the DQN. If we include the choices of operations in our search space, our method is inferior to some state-of-the-art methods, but still shows better performance than random search and policy-based REINFORCE proposed by NAS-Bench-101. |
Distributional Tsallis Actor-Critic (Jaeyeon Jeong)
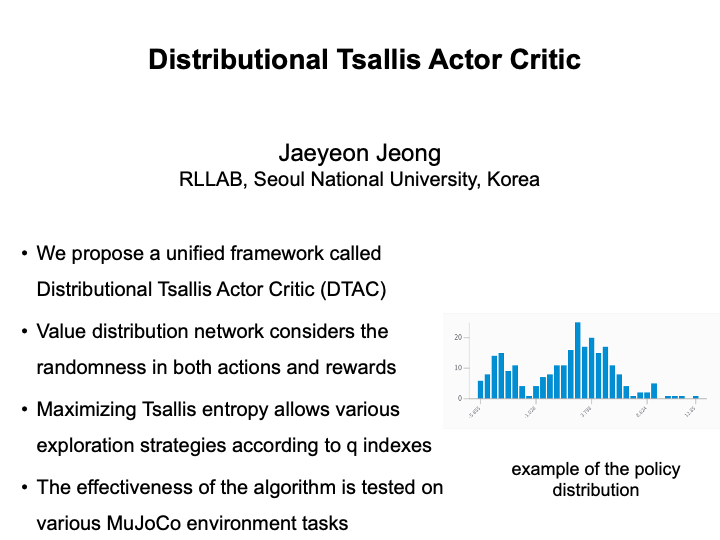
In this paper, we present a unified framework for maximum entropy regularization reinforcement learning called Distributional Tsallis Actor Critic (DTAC). DTAC uses the distribution of the value function and maximizes the tsallis entropy to encourage exploration while considering the randomness in both the value and the action and the rewards. Also, by using the risk-sensitive network by using the distorted expectations, various risk sensitive or risk-averse policies can be introduced, and such policies are strengthened by the value distribution itself. Experiments on mujoco environment performed shows various behaviors learned by the trained policies. |
End-to-end Waveform Generation for Improvising a Musical Instrument (Jinwoo Lee)
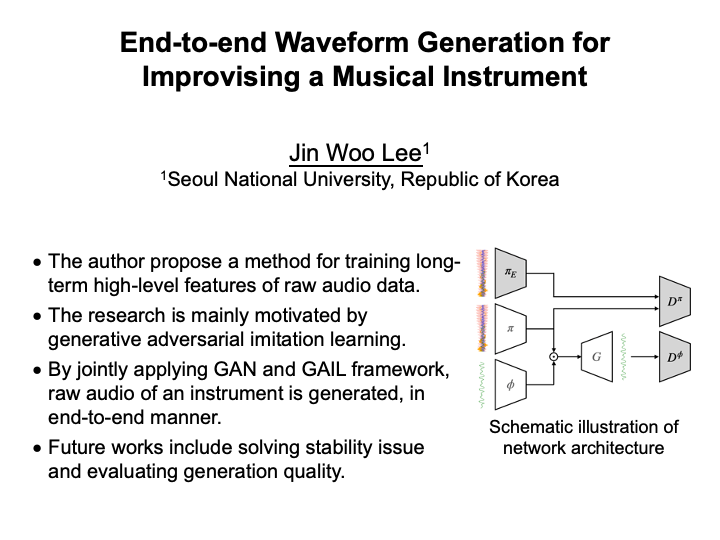
Audio signal is a time-varying sequential data equipped with high-level features such as linguistic or musical structures, nuisances, and emotions. Extracting the high-level features directly from the raw waveform is sample inefficient, and requires a neural network to have incredibly large receptive fields. The problem for effectively taking large receptive field (RF) in raw wave signals have been studied in variety of approaches. This paper propose a method for training long-term high-level features of raw audio data, based on theories of reinforcement learning and adversarial learning. By jointly applying generative adversarial learning and generative adversarial imitation learning, the agent learns to generate a waveform of a musical instrument's play, by extracting high-level audio features directly from the waveform. Future works include solving the stability issue for the training, and evaluating the generation quality. |
Image Goal Navigation Using Keypoint Detection and Map Prediction (Jaeseok Heo)
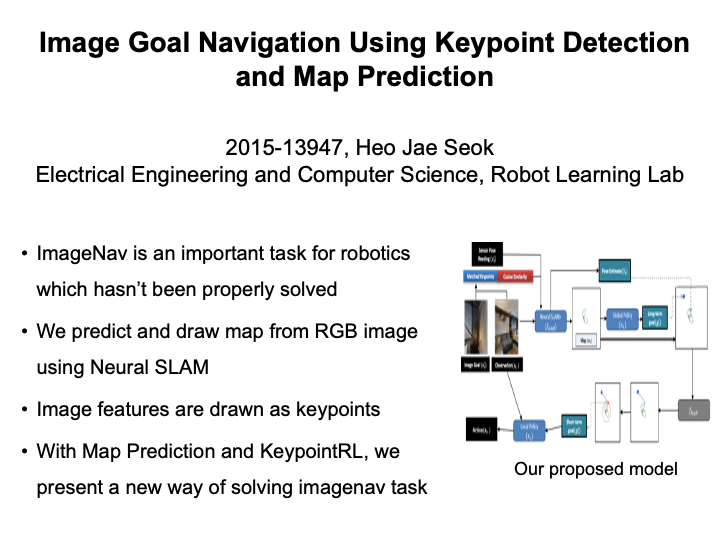
In this task, we tackle the problem of Image-Goal Navigation, where an agent is asked to find the viewpoint of the given goal image in an unseen environment. Past methods rely on depth cameras, require panoramic observations, a pre-built graph network, or is trained on limited situations where the image-goal viewpoint is close to the initial agent state. Our method uses metric maps built by RGB images by a Neural SLAM network and image descriptors extracted from place recognition networks such as NetVLAD and SuperPoint. We have trained a policy network which collects the SLAM Map, information about matched keypoints and global descriptors between the observation and goal image andputs out a global goal which guides the agent to the image goal. Our method is trained and on a self-made imagegoal dataset based on the gibson datset which contains images of the best viewpoints of semantic obstacles and is shows that using such global policy gives improved performance compared to its counterparts. |
Influence based Reward for Communicative Multi-Agent Reinforcement Learning (Minyoung Hwang)
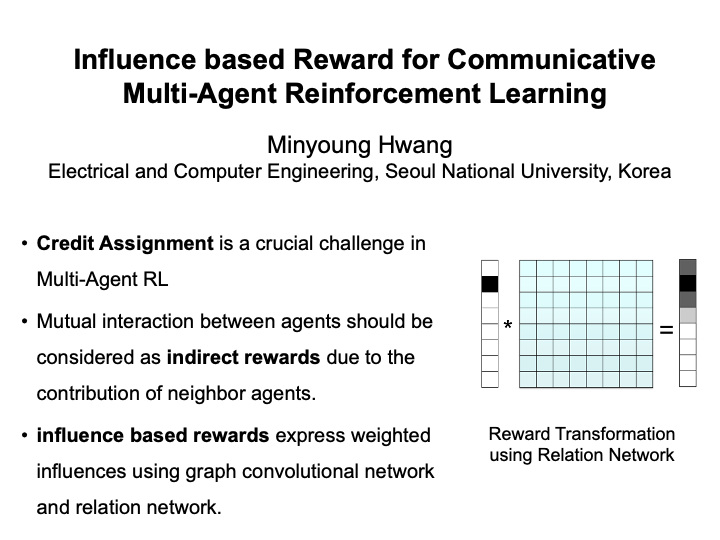
Credit Assignment is a crucial challenge in Multi-Agent Reinforcement Learning. The key to solve this problem is considering mutual interaction between agents. When multiple agents are collaborating with each other by sending information, neighbor agents have their contribution to individual sparse rewards. In this project, we develop influence based rewards using graph convolutional network and relation network. Graph convolutional network shows the overall dynamics of the multi-agent environment and learns cooperative communication between agents. Interaction between agents is learned and expressed by relation network. The output of this network, relation matrix helps calculating weighted influences from each agent's neighbors. We compare our method with existing Multi-Agent RL methods, and address that it is scalable to various graphical communication structures. |
Learning multiple gaits of quadruped robot using hierarchical reinforcement learning (Yunho Kim)

Designing a velocity command tracking controller that generates optimal gaits of quadruped robot is crucial for quadruped robot application. Previous works focused on manually generating gait features or fine tuning costs for each gait to generate multiple gaits in a separate manner [13], [14], [15]. However, they all didn't considered the existence of optimal gait for specific velocity range which is well known in both biomechanics and robotics community. In this work, we propose a hierarchical controller for quadruped robot that could generate multiple gaits (i.e. pace, trot, bound) while tracking velocity command. Our controller is composed of two policies, each working as a central pattern generator and local feedback controller, and trained with hierarchical reinforcement learning. Experiment results show 1) the existence of optimal gait for specific velocity range 2) the efficiency of our hierarchical controller compared to a controller composed of a single policy, which usually shows a single gait. |
Learning to Skip Empty Feature Maps (Nghia Tuan Nguyen)
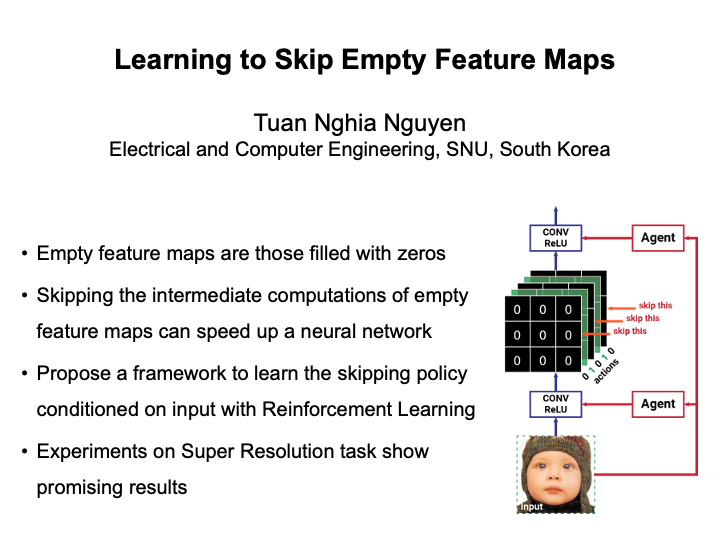
We introduce a method that exploits the sparsity of output feature maps to reduce the computational cost of a neural network. In this method, an agent is integrated into the core network as a controller. In prior to the inference phase of the core network, the agent determines, conditioned on the input, whether to fill a specific feature map with zeros instead of doing actual intermediate computations. The agent is trained with reinforcement learning to optimize the trade-off between accuracy and efficiency. The proposed method is applied to improve the inference speed of the SVDSR-10 network on the Super Resolution task. We conduct experiments on Set-5 and Set-14 to evaluate the effectiveness. |
Meta Learning with Deep Elastic Networks (Hongjung Lee)
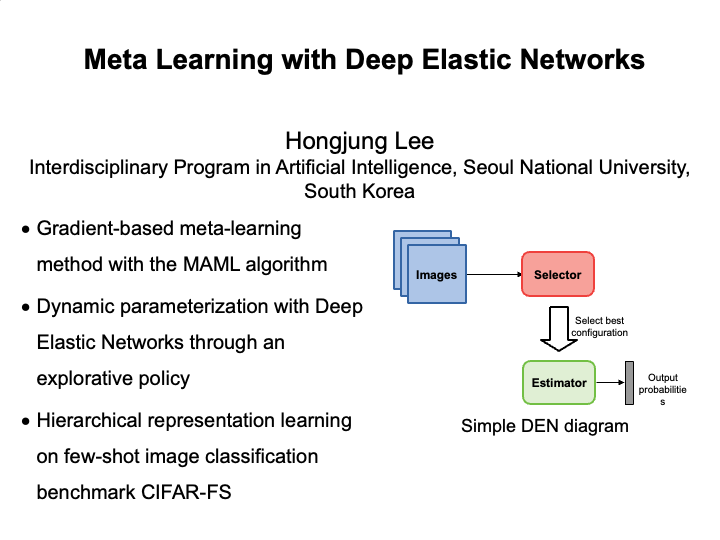
Conventional deep learning methods excel at learning a single task, but have tendencies to overfit to the given data. Meta-learning methods address this issue by learning to find the best learning algorithm that solves such task. Gradient based meta-learning algorithms have shown to be effective in few-shot learning tasks. By combining the MAML algorithm with Deep Elastic Networks (DEN), a convenient network architecture to learn hierarchical representations consisting of a selector network and an estimator network, we propose an effective meta-learning algorithm that allows for a dynamic representation on prior tasks. The selector network aims to find the combination of parameters in the estimator network with best performance on a given task. We compare this approach against existing methods on a few-shot image classification benchmark (CIFAR-FS). |
Miniature Wargame "Warhammer 40,000" environment for deep reinforcement learning (Flin Hoepflinger)

Monte-Carlo Skill Chaining from Fragmented Demonstrations (Minjae Kang)

In general, most tasks in the real world require the agent to perform a variety of skills. However, it is challenging to cover all the different skills with a single policy of agent. As one way to solve this problem, a study of skill chaining has been studied to learn skills individually and find the order of skills. Under the assumption that independent demonstrations exist that perform each simple task, we want to form a skill chain that performs a complex task using the skills learned from them. In this paper, we propose a method to form a skill chain through the hierarchical structure of the low-level, which directly controls an agent, and the high-level, determining the skill order. First, at low-level, we learn skills to use in a skill chain formation. We define low-level skills separately into the base skill learned from fragmented demonstrations and the bridge skills that connect incompatible base skills. Bridge skills are trained through reinforcement learning, and rewards are given depending on the success of the following base skills. Next, a high-level planner determines the performance order of skills. Unlike the base skills, which are pre-trained and fixed, the bridge skills are simultaneously trained with a high-level policy, so dynamic at high-level is highly unstable. We solve this problem through Monte-Carlo tree search (MCTS). First, observations can be allocated to a finite number of nodes by clustering independent demonstrations. As a result, it is limited to only a finite number of node-skill pairs so that MCTS can be applied. In the experiment, we perform a block stacking task with RGBD images as input in the Baxter simulator. We show that our proposed method can successfully form skill chains from only fragmented demonstrations. |
MPC-assisted Meta-Reinforcement Learning for Safe Navigation (Astghik Hakobyan)
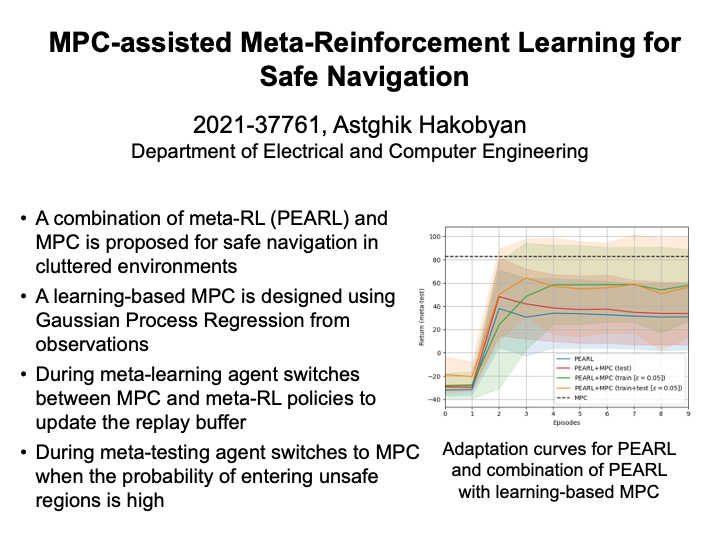
In this work, we propose a novel MPC-assisted Meta-Reinforcement Learning (meta-RL) scheme for safe navigation in cluttered environments. This is achieved by combining a state-of-the-art meta-RL algorithm called probabilistic embeddings for actor-critic RL (PEARL) with a learning-based model predictive control (MPC) to improve sample efficiency of the meta-training process, as well as advocate exploration in high-reward regions. This is achieved by learning the transition probability of the agent via a Gaussian Process Regression (GPR) and solving a stochastic MPC problem during the meta-training iterations. Additionally, during the meta-testing, a collision-triggered learning-based MPC is applied to the agent to ensure safety near unsafe regions. Such an approach provides a safety guarantee as well as promotes fast adaptation. Experiment results demonstrate the utility of the proposed method by the means of comparison with the baseline PEARL algorithm, as well as pure learning-based MPC. |
Mutual Information State Intrinsic Control (MUSIC) improvements with Sparse Tsallis Entropy Regularization (Jongkook Kim)

Mutual Information State Intrinsic Control(MUSIC) is one of the first intrinsically motivated RL algorithm that proved successful in Robotic Manipulation Tasks. MUSIC utilizes agent-surrounding separation to compute mutual information between the two and use it as an intrinsic motivation. While Soft-Actor-Critic version of the algorithm is better performing than its DDPG version, having a “dense” stochastic policy(as is used in SAC) seems to hinder its performance in various situations. Especially in robotic manipulation, too much of stochasticity in it policy may hinder its applicability in real situations. This project applies Tsallis Entropy Regularization to the MUSIC algorithm and shows improvements in its performance in FetchPush-v1, FetchSlide-v1, FetcchPickandPlace-v1 tasks. |
Neural Gaussian Random Path Policy (Jeongwoo Oh)

In reinforcement learning, a paradigm of recent sensorimotor control, policies learn directly in the raw action space. However, in this case, there are limitations for continuous, high dimensional, or long-horizon tasks. Therefore, decision making in trajectory space is important. But, transformation from the trajectory space to action space is different for each environment, and has the disadvantage that it changes whenever the agent parameter changes. On the other hand, the Gaussian Random Path is an algorithm that generates a path using several anchors, and the path changes sensitively depending on anchors. In this paper, we developed an algorithm that can be controlled agent without transformation from trajectory space to action space by Gaussian Random Path, and anchors are calculated by neural network. Also, we compared and proved that our algorithm performs better than previous algorithms. |
Policy Gradient Attack Against Out-of-Distribution Detectors (Sangwoong Yoon)

Out-of-distribution (OOD) detection is the task of determining whether an input lies outside the training data distribution. As an outlier may deviate from the training distribution in unexpected ways, an ideal OOD detector should be able to detect all types of outliers. In this paper, we propose policy gradient attack against OOD detectors, where we use reinforcement learning to synthesize a novel images that an OOD detector would misclassify. Using policy gradient attack, we investigate OOD detectors with reported near-perfect performance on standard benchmarks like CIFAR-10 vs SVHN. Our methods discover a wide range of samples that are obviously outlier but recognized as in-distribution by the detectors, indicating that current state-of-the-art detectors are not as perfect as they seem on existing benchmarks. |
Risk-aware Trading Agent using Reinforcement Learning (Jungsub Rhim)

Robust Control with Grounded Action Transformation using Gaussian Blurring (Sumin Lee)
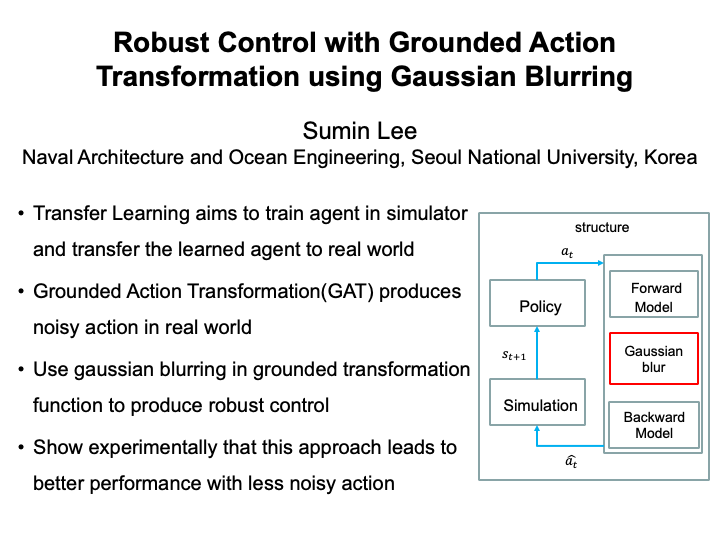
In the field of robot learning, it is very expensive to train a robot in a real environment. Therefore, . Grounded Action Transformation(GAT) uses action transformation function to transform the simulation action into real action. GAT produces noisy action which could affect the performance in real environment. In this work, to produce less noisy actions in real environment, I use gaussian blurring to grounded transformation function to make action transformation function. Gaussian blurring reduces noise in the grounded transformation function. In experiment, I applied this to RC car driving task. The agent is trained in GAZEBO simulator and tested with RC car in real environment. I show experimentally that this approach leads to better performance with less noisy action. |
Standoff Tracking Using Vector Fields Guidance with Reinforcement Learning (Hyeong-gwan Kang)

A reinforcement learning scheme of vector field for standoff tracking is proposed in this paper. In standoff tracking problem, a fixed wing UAV continuously tracks a target while maintaining a fixed distance between the UAV and the target. The input of UAV is determined by a desired velocity of the UAV, which is determined for each position by a vector field. In this paper, the coefficients of vector field is determined by using deep deterministic policy gradient (DDPG) algorithm, and the performance of the vector field is verified using numerical simulations. |