
Class Project
Information
- Date: 2020/06/17 (Wednesday)
- Time: 11:00AM - 1:00PM
Session 1: Q learning and Exploration
- Q Learning to Find Optimal Look Ahead Distance in Pure Pursuit Steering Control Mode (윤창호)
- Multiple Deep Q-Learning – A Multi-Network Relaying Version of DQN (Bo Han Chen)
- Object Localization with Double Deep Q-Learning (하태길)
- Gaussian Process based Hindsight Experience Replay (오우석)
- Exploration-Exploitation Trade-off in Practical Deep Reinforcement Learning Approaches for Stock Trading (Bui Tien Cuong)
- Confidence-Based Actions Selection for Exploration in Deep Reinforcement Learning (윤형석)
Session 2: Imitation, Transfer, Multi-task, and Causal Learning
- Improving Stochastic Policy for Imitation Learning on Physical Constraint Control (유세욱)
- From Human Gesture to Quadruped Robot Motions Learned by Imitating Animals (김선우)
- Generative Adversarial Imitation Learning with Incomplete expert (황인우)
- Zero-Shot Transfer Learning of a Throwing Task via Domain Randomization (박성용)
- Continual Reinforcement Learning with Dirichlet Process Mixture (장동수)
- Causal Reasoning in Reinforcement Learning (최진우)
Session 3: Robots and Safe RL
- End-to-End Reinforcement Learning for Autonomous Driving in CARLA (김찬)
- Learning to Walk in a Physics Simulation using Reinforcement Learning (장필식)
- RL4RL: Optimal Representation Learning for Optimal Policies in Partially Observability (민철희)
- Safe Guided Policy Optimization (김도형)
- Task-agnostic global safety priors for safe reinforcement learning in self-driving (김경도)
Session 4: Computer Vision and Network Architecture Search
- Kernel Estimation Using Self-Supervised Deep Reinforcement Learning (조선우)
- Gaussian RAM: Lightweight Image Classification via Stochastic Retina Inspired Glimpse and Reinforcement Learning (심동석)
- Actor-Critic Using the Stochastic Policy in Continuous Action Space for Reinforcement Learning in Video Grounding (김선오)
- The Difficulties of Image Observations in RL by Flappy Bird (Duong Tung Lam)
- Reinforcement Learning from Data Meta-features to Automate Machine Learning (ML) Pipeline (Van-Duc Le)
- Dynamic Block-Sharing Residual Networks (Thanh Hien Truong)
Session 5: Applications
- Imitating occupants’ cooling control in house (신한솔)
- Single-agent vs. multi-agent reinforcement learning for district building energy management (고윤담)
- A Deep Reinforcement Learning Chatbot Leveraging Online Communities Posts (조시현)
- Exit-Time Reinforcement Learning: Practical Issues (김진래)
- Bimanual manipulation by learning task schema (조대솔)
Zero-Shot Transfer Learning of a Throwing Task via Domain Randomization (박성용)

Learning continuous robot control has been a wide interest in the past few years. Collecting data directly from real robots raises high sample complexities and safety problems so simulators are widely used as one of the most important tools for efficient reinforcement learning in robotics. Unfortunately, in many cases, polices learned in the physical simulator are not transferable to the real world robot due to a mismatch between the simulation and reality, called ‘reality gap’. To close this gap, domain randomization (DR) can be used which is a popular technique for improving transfer capabilities between different domains, often used in a zero-shot setting, i.e. when a policy is learned in a source domain and is tested in a previously unseen target domain without finetuning. In this work, the effectiveness of DR for zero-shot transfer to target domain is demonstrated on an object throwing task, which is rarely selected as a performance test. |
Q Learning to Find Optimal Look Ahead Distance in Pure Pursuit Steering Control Mode (윤창호)

To apply the geometric based lateral controls in real world, some parameters should be obtained through experimentations. Look-ahead point is a key component used in the pure pursuit control and indicates a control point located on the reference path in front of the vehicle rear axis. Depending on the look ahead distance, the vehicle shows different working trajectories. This study aims to achieve an automatic tuning of the look-ahead distance using Q learning in a 3D tractor simulation. The elements of the reinforcement learning are described as following: - Agent: tractor working model based on pure pursuit kinematic bicycle model - Action: Different look ahead distances - Environment: Tractor simulator slip applied 3D terrain model - State: location of tractor from a reference path - Reward: grade of lateral deviation, hitting boundary or no The result has not shown any improvements at this time because there has been a critical mistake that the steering model applied for the simulation is a PD controller not the pure pursuit: this is not different with tuning the derivative term and it is not meaningful. Although it has failed to report results with a right way and it takes a lot of time to construct a simulation with the reinforcement learning, in the future, there will be an effort with a better model such as model based reinforcement learning with model predictive control. |
Multiple Deep Q-Learning – A Multi-Network Relaying Version of DQN (Bo Han Chen)

In this work, I propose an algorithm of Deep Reinforcement Learning. It is aiming for fixing the overestimation problem in Deep Q-Learning. The proposed algorithm in this paper, Multiple Deep Q-Learning, is a architecture based on the modification of Double Deep Q-Learning. Multiple Deep Q-Learning is training a set of Neural-Networks sequentially, and relaying the target net between the displacement. This methodology allow the chosen action not very biased. We test our algorithm on the ATARI 2600 games "Wizard Of Wor", with several different combination of hyperparameters. The result shows Multiple Deep Q-Learning is competitive with Double Deep Q-Learning. |
Gaussian Process based Hindsight Experience Replay (오우석)

In Reinforcement Learning, efficient exploration still remains a major challenge. ε-greedy exploration and adding Gaussian noise to actions are popular heuristic exploration algorithms, but in tasks that have a sparse reward, this methods may be slow or sometimes may not be able to learn at all. Intrinsic Motivation method are often used to solve this problem. Hindsight-Experience-Replay(HER) is one of the algorithms to use intrinsic motivation, which makes it possible to learn how to get the desired outcome quickly using the experiences from undesired outcomes. However, in order to use the HER, you must know the goal state in advance. We propose a way to efficiently explore using HER without knowing the goal state. Instead of the goal state, we used unvisited states as the temporary goal of the HER for exploration. In the process, the Gaussian Process regression was used to approximate the reward function, and the state with high-variance in the estimated reward function was used as the goal of the HER. We perform experiments on the MountainCar-v0 environment in gym, which has sparse reward. We show that our method is comparable to HER even without knowing the goal state. |
Imitating occupants’ cooling control in house (신한솔)

In the past 30 years, a lot of efforts have been made to analyze the cause of the building energy use and reduce the energy use using a building energy simulation (e.g. ISO13790, EnergyPlus). However, there is a significant performance gap between the real building and the virtual building model, which are due to unpredictable occupant behavior. If it is possible to simulate the occupant behavior and if know the occupant's reward function, it can bridge the gap caused by the occupant behavior. In this study, the cooling control of the occupants simulated using the building energy simulation model (EnergyPlus). And simulating the cooling control of the occupants using Generative Adversarial Imitation Learning (GAIL) which is one of the inverse reinforcement learning algorithm. |
Kernel Estimation Using Self-Supervised Deep Reinforcement Learning (조선우)

Super-Resolution methods typically assume that the low-resolution image was degraded from the unknown high-resolution image by "bicubic" downscaling. However, this induces domain gap between training low-resolution image datasets and real scenario's low-resolution test image which can be rather downsampled from arbitrary kernel. Consequently, the needs of correct estimation of the kernel of real scenario have appeared recently. "KernelGAN" [1] estimates Kenrel which makes low-resolution image to locate in the same domain of high-resolution image. However, using Generative Adversarial Network (GAN) for estimating kernel is unstable, which induces large variance of accuracy of estimated Kernel. In this paper, we adopt Reinforcement Learning Algorithm to estimate accurate Kernel with one guidance image.We assume kernel to be in the set of anisotropic gaussian and find optimal theta, and l1, l2 parameter. For simplified case, we find only one parameter l2, with fixed l1 and theta. |
Learning to Walk in a Physics Simulation using Reinforcement Learning (장필식)

Using a policy-based reinforcement learning algorithm (PPO), we were successfully able to train a humanoid agent to walk with joint torque control, using an imitation learning approach called DeepMimic. The environment is implemented in the PhysX physics engine, which is first of its kind; previous works on DeepMimic were implemented in Bullet and DART. Several improvements to the DeepMimic method are tested, such as modifications to stable PD control, and change of state/action space and algorithm. Firstly, we correct the stable PD controller by properly considering the floating-base degree of freedoms from the Newton-Euler dynamics equations. Also, multiple experiments are performed to examine whether different reward terms and state spaces proposed from recent papers improve the training process. Lastly, other RL algorithms such as off-policy algorithms like DDPG and TD3) are tested to see if it improves the training of the controller.
|
A Deep Reinforcement Learning Chatbot Leveraging Online Communities Posts (조시현)

Can a robot be a personal dating coach? Even with advances in natural language processing algorithms, the implementation of conversational robots remains a challenge. In this paper, we present a DBO: a Deep reinforcement learning chatBOt for dating coaching scenarios leveraging corpus from three online communities. We define a short text conversation task as a selecting a response maximizing expected user score for a given query. We examine people's responses to the dating coaching robot with a dialogue module. 97 participants joined to have a conversation with the robot and 30 of them evaluated the robot. The results indicate the participants thought the robot could be a friendly dating coach while considering the robot is entertaining rather than helpful. |
Continual Reinforcement Learning with Dirichlet Process Mixture (장동수)

Continual learning aims to learn from non-iid stream of data without forgetting the formerly learned data. In many reinforcement learning settings, the agent observes states that are highly correlated with the previous states. When the policy or the value is learnt naively, the data acquired by encountering scenarios are autocorrelated, resulting in catastrophic forgetting. The objective of this project is to create a model that can learn online in the Bayesian nonparametric framework, which determines the models complexity adaptively in a task-free manner. Specifically, we propose to apply the Dirichlet process mixture model to reinforcement learning framework by continually learning the policy network. |
Exit-Time Reinforcement Learning: Practical Issues (김진래)

Exit-time setting for real-world reinforcement learning tasks is investigated through a numerical simulation. The Exit-time reinforcement learning problem is that an agent makes decisions until exit a set, which may be a safety zone; it is usually adopted in dynamical system control. In the simulation, modified advantage actor critic algorithm for exit-time setting is applied to train a triple integrator system, which is simple but highly unstable. From the simulation result, it is revealed that a time over condition may yield significant performance degradation when implementing standard reinforcement learning algorithms such as actor-critic methods.
|
Improving Stochastic Policy for Imitation Learning on Physical Constraint Control (유세욱)

Stochastic policy is utilized in reinforcement learning or imitation learning to find a optimal policy. However, in case of holonomic robots like autonomous vehicle that has the physical constraint, boundary effect results in critical behavior to find the optimal policy. so, we need to choose distribution properly considering robots’ characteristic. Generally, gaussian distribution have been used for policy. This is because it is easy to sample and to compute gradient. However, it is biased estimation and high variance to compute gradient because of the boundary effect. We propose new policy distribution for imitation learning as using the beta policy. As a result, we propose bias-free method without increasing the variance. |
Causal Reasoning in Reinforcement Learning (최진우)

Most reinforcement learning algorithms are tested in environments such as gym, atari, and mujoco. This environment is different from the real-world. In each experimental environment of gym and mujoco, the input state is predefined. However, it is difficult to define an observation state in a complex real-world. Among the states that are considered to be important for human judgment, it may not be necessary to train the agent, or it may degrade learning. This has already been demonstrated in imitation learning. In this paper, we confirmed whether the same results were found in reinforcement learning and conducted a study on how to solve them. Since there is no ground-truth for the required state in the real environment, the results in vanilla PG and TRPO were analyzed by adding the previous action and noise state in addition to the predefined input state in the mujoco environment. We also looked at the changes when dropout was applied. |
RL4RL: Optimal Representation Learning for Optimal Policies in Partially Observability (민철희)
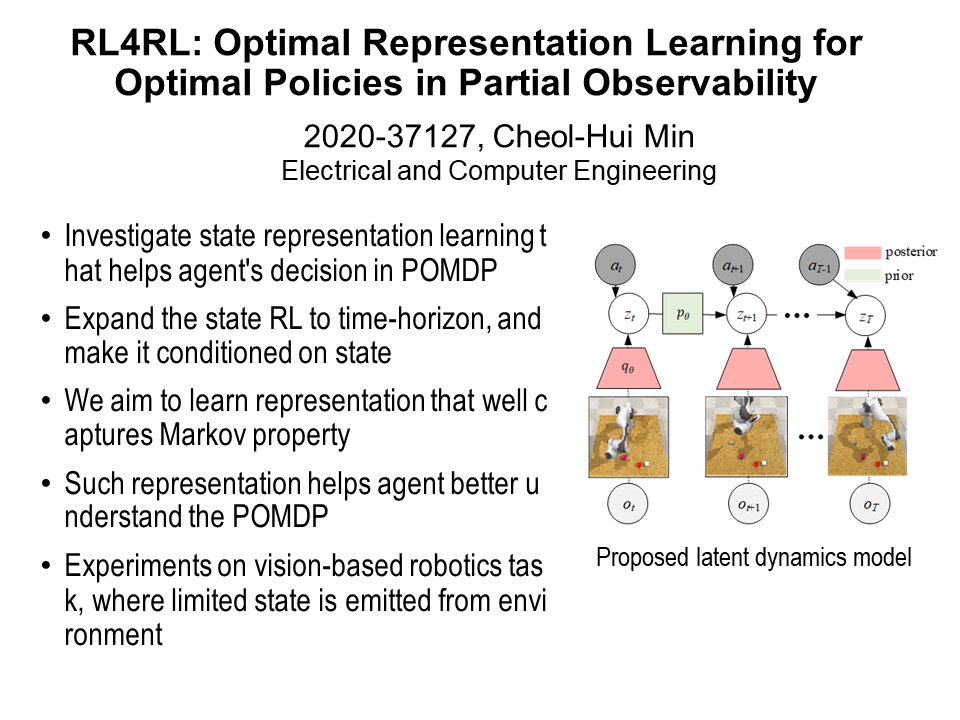
Deep reinforcement learning (DRL) has been successfully applied to many robotics control problems owing to the success of deep neural networks, the powerful non-linear function approximator. However, it is still a challenging task for the robot agent to infer optimal action from visual observation, since the visual observation is much high-dimensional, barring the agent from the immediate access to the true state of the environment. To tackle this problem, a state-representation learning (SRL) in the generative model domain has been utilized to map the high-dimensional observation to low-dimensional space. In this project we investigate a set of representation learning models to maximize the performance of robot agent’s control from visual observation. |
Object Localization with Double Deep Q-Learning (하태길)

Object localization is so far carried out with with neural networks such as region proposal netork(RPN) in deterministic model and showed successful performances. However, most RPN demands pre-defined anchor boxes and fixed aspect ratio and sizes which defines it's limit itself, and it lacks of human-like behavior and still the investigation about how RPN localizes object. Active Object Localization has succeed to deal with the localization with deep Q-learning, which is similar to human eyes' localization process - from coarse location to fine location. Though it shows pretty good performance, we can still boost the performance with better Reinforcement learning algorithm. Here I applied Double Q-Learning into object localization task, which boosted mAP into 50.7% from 45.5%, suggest that better RL technique can boost localization performance. |
Reinforcement Learning from Data Meta-features to Automate Machine Learning (ML) Pipeline (Van-Duc Le)

Machine Learning (ML) pipeline is a sequence of steps to solve a ML problem from data pre-processing, features transformation to model selection, model training (hyper-parameters optimizing), and get the desired outcomes (e.g. accuracy). Recently, the tasks of model selection and hyper-parameter tuning have been automated by using some methods such as AutoML or Neural Architecture Search (NAS). Nevertheless, the mentioned methods mostly focus on finding a good model for a ML dataset and assume that the data was already processed before entering the model. In reality, the pre-processing and features transformation steps are important tasks to make a good ML model. Clearly, these steps depend on the characteristics of the input data such as the data meta-features (e.g. number of features, types of features, the features distribution, to name a few). In this project, I will try to automate the whole ML pipeline by learning from data meta-features using Reinforcement Learning (RL). Specifically, I will use Policy Gradient methods such as the REINFORCE algorithm with the policy is represented by a Deep Neural Network (DNN) such as a 2-layer Fully Connected NN or a sequence-to-sequence Recurrent Neural Network. I train the policy gradient with nearly 100 collected real-world ML datasets and test with other 15 datasets. Although the results are quite limited because of the not-yet-optimized policy models, they show that RL can be used to automate the whole ML pipeline for real-life ML problems by learning the data meta-features. This result could be applied to planning problems that try to forecast new business plans based on the historical business data. |
Exploration-Exploitation Trade-off in Practical Deep
Reinforcement Learning Approaches for Stock Trading (Bui Tien Cuong)

Applying deep reinforcement learning algorithms to the stock trading problem is interesting but challenging. Therefore, it demands a well-constructed model that can represent all critical factors of the problem and provides robust performance under uncertain conditions. In this paper, we first formulate the stock trading problem as a Markov Decision Process with a corresponding maximization problem. We introduce a well-known method for solving continuous the action spaces Deep Deterministic Policy Gradient, and later our main focus method off-policy maximum entropy Soft Actor-Critic (SAC). We conduct numerous experiments to demonstrate both weaknesses and advantages of SAC and other state-of-the-art methods in deep reinforcement learning for the continuous action-space problem. Our experimental results show that applying deep reinforcement learning to the stock trading problem is a promising research direction. |
From Human Gesture to Quadruped Robot Motions Learned by Imitating Animals (김선우)

Controlling robot motion skills has remained challenge in robotics field. Some research tried to reproduce agile locomotion skills by imitating animal in physics simulation. Kinematic controllers for reproducing such motion are unstable. Manual designing of such controllers involves difficult process with expertise leading time consuming. Reinforcement learning automated this process from manual labor providing adaptable controllers. Recent state of the art research showed the learning agile robotic locomotion skills by imitating animal. However building a controller of these skills remained to be unsolved. In this project, I improved current state of the art paper while modifying retargeting algorithms and adding action normalize scheme into proximal policy algorithm. Also, this process had implemented to adapt in a new environment and a robot. Finally, this research showed the possibility of mapping human gesture to quadruped robot imitated motion. |
Safe Guided Policy Optimization (김도형)

In Reinforcement Learning (RL), exploration is essential to achieve the globally optimal policies. However, the agent should operate in safe regions because the exploration can harm people or damage itself. To this end, safe RL has been introduced, but it deals with trajectory-wise constraints or uses just one step prediction, so it can only be applied under certain conditions. To handle step-wise safe constraints, model based methods using optimal control such as Linear Quadratic Regulator (LQR) can be used, but solving optimal problems at every step requires a lot of computation that makes real time control unfeasible. Thus, in this paper, constrained LQR for safe exploration is approximated using the safety layers, which is introduced in [1], to enable real time control, and the policy with the safety layers serves as a guide to the original policy. |
The Difficulties of Image Observations in RL by Flappy Bird (Duong Tung Lam)

Reinforcement learning is one of the most popular approaches for automated game playing and have yielded state of art results. However, most of the result comes from the well-known observations in the environment such as positions, velocities and so on. This approach makes the learning easier to handle by reduce the dimension the agent has to cope with, but it also consume lots of time for environment handcrafting and misses the realistic scope. For particular games with a vast of environment space with multiple actions, it is beneficial to help the agent learn to play the game dynamically by observed images. In order to measure the difficulties of using images in particular, Flappy Bird environment is a baseline to estimate when this is a simple game with only binary state of action, but also has a heavy relation between the quality of actions and environment rewards. In addition, bad Flappy Bird actions can lead to terminal state quicker than Artari games which sometimes allow ’noob’ movement to occur without any termination. Asynchronous Actor-critic Agent (A3C) is used as the backbone with the aim to control the bird fly through the floating pipes by images as long as possible. Model then contains convolution neural network for action selection and soft-critic generation; long-short term memory for clipping critic prediction. However, due to the noise of background and variance of colors in images, the agent has failed to converge and only bypass to 5 pipes while a simple of Q-learning agent with observations from objects locations can reach a state of art result. Further improvement such as fine-tuning ,stacking more layers or apply computer vision detection method can be done to overcome the prior result to help the agent has better realization on the observations. |
Confidence-Based Actions Selection for Exploration in Deep Reinforcement Learning (윤형석)

How to explore environments is one of the most critical factors for the performance of an agent in reinforcement learning. Conventional exploration strategies such as $\epsilon$-greedy algorithm and Gaussian exploration noise simply depend on pure randomness. However, it is required for an agent to consider its training progress and long-term usefulness of actions to efficiently explore complex environments, which remains a major challenge in reinforcement learning. To address this challenge, we propose a novel exploration method that selects actions based on their confidence. The key idea behind our method is to estimate the confidence of actions by leveraging zero avoiding property of kullback-leibler divergence to comprehensively evaluate actions in terms of both exploration and exploitation. We also introduce a framework that allows an agent to explore efficiently in environments where reward is sparse or cannot be defined intuitively. The framework uses expert demonstrations to guide an agent to visit task-relevant state space by combining our exploration strategy with imitation learning. We demonstrate our exploration strategy on several tasks ranging from classical control tasks to high-dimensional urban autonomous driving scenarios at roundabout. The results show that our exploration strategy encourages an agent to visit task-relevant state space to enhance confidence of actions, outperforming several previous methods. |
Task-agnostic global safety priors for safe reinforcement learning in self-driving (김경도)
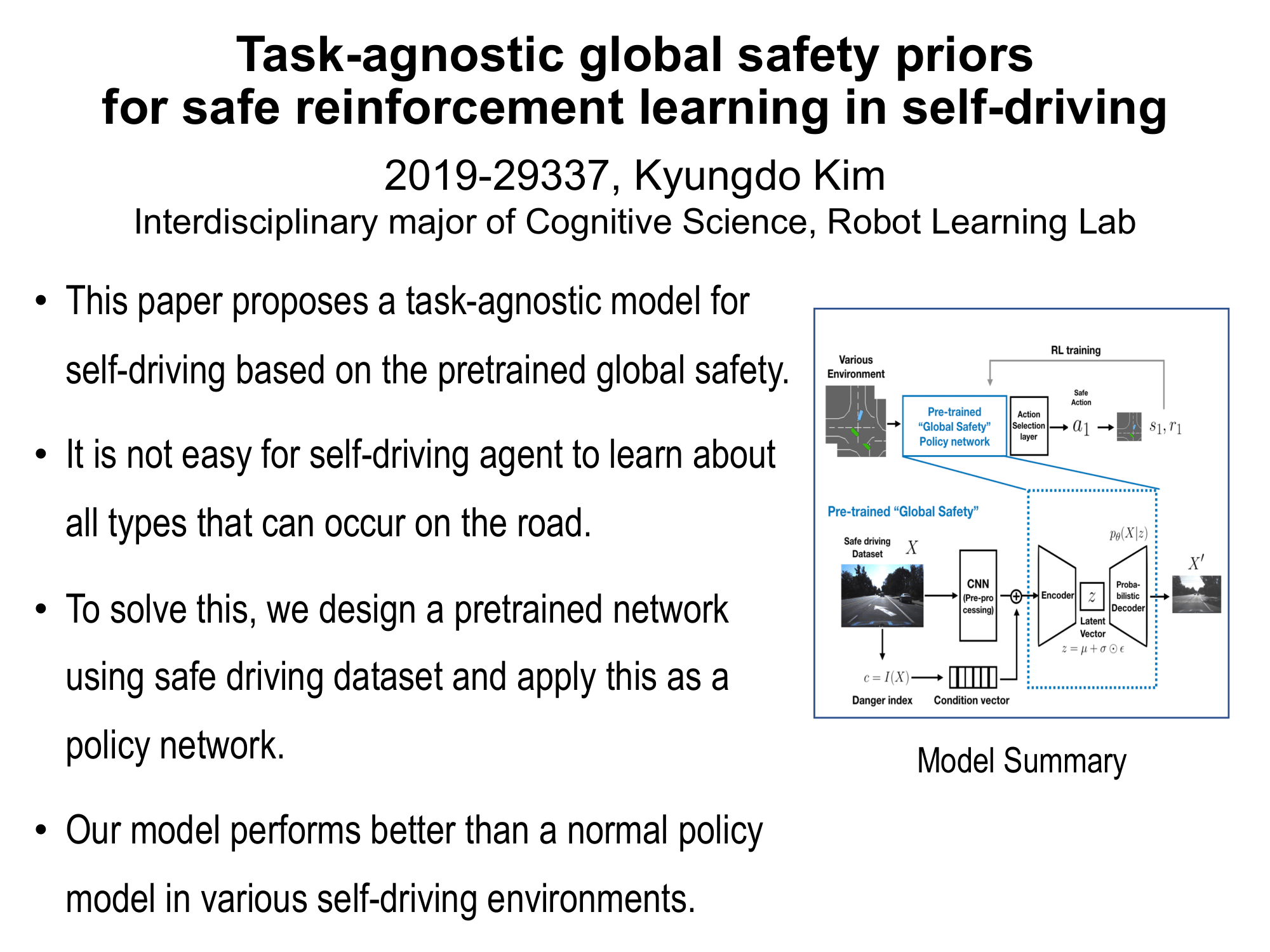
This paper proposes a task-agnostic model for self-driving based on pretrained global safety prior. For a safe autonomous vehicle system, the agent must be trained in all possible situations on the road. However, such training is not easy to divide each case of the circumstance and takes a lot of time. To solve this, we suggest a global safety prior model and apply this model into various autonomous driving cases. The model composes pretrained network based on safely driven data by humans. This network has a conditional variational autoencoder(cVAE) part to learn global safety features from the dataset and can be applied as a prior to various tasks. This model is used as a policy network for reinforcement learning in different autonomous driving simulations. Our model achieves better results than using the simple policy network and also shows an advantage in convergence. |
Single-agent vs. multi-agent reinforcement learning for district building energy management (고윤담)

Buildings consume more than 40% of total primary energy use, and heating, ventilation, and air conditioning (HVAC) systems accounts for about 30% of building energy use. Therefore, building controls should be well performed for energy saving and comfortable indoor environment. However, energy systems and networks of buildings are becoming complicated by integration of new technologies, such as smart home and smart grid. Reinforcement learning (RL) attracts attention in the research community as an inexpensive plug-and-play controller that can be easily implemented in any building regardless of its model. In this study, Twin Delayed Deep Deterministic Policy Gradient (TD3) was applied to control the cooling systems of eight buildings to achieve two goals: save cooling energy, and reduce average daily peak demand. Multi-agent (MA) TD3 taking a vector of eight actions to receive a vector of eight rewards was implemented in CityLearn environment, and single-agent (SA) TD3 taking only one action for all eight buildings was used as a baseline. As a result, by using MA TD3, about 2% of cooling energy in a week was saved, and average daily peak demand was reduced by about 5%. |
Gaussian RAM: Lightweight Image Classification via Stochastic Retina Inspired Glimpse and Reinforcement Learning (심동석)

Previous studies on image classification are mainly focused on the performance of the networks, not on real- time operation or model compression. We propose a Gaussian Deep Recurrent Visual Attention Model (GDRAM) - a reinforcement learning based lightweight deep neural network for large scale image classification that outperforms the conventional CNN (Convolutional Neural Networks) which uses the entire image as input. Highly inspired by the biological visual recognition process, our model mimics the stochastic location of the retina or visual attention with Gaussian distribution. We evaluate the model on Large cluttered MNIST, Large CIFAR-10 and Large CIFAR-100 datasets which are resized to 128 in both width and height. |
Dynamic Block-Sharing Residual Networks (Thanh Hien Truong)

The dynamic neural architecture solution, BlockDrop, addresses instance-specific difficulty by generating an inference path for each input such that some blocks are skipped while the others are maintained. The method successfully reduces a considerable amount of computational expense and speeds up very deep residual networks. However as all blocks in the original model are still utilized at some moments, the usage of memory does not change. In this project, we investigate a new dynamic network approach that aims to reduce the memory requirement for deploying deep neural networks. Starting with a model of decent depth, the proposed method allows the network to expand the capacity and generates instance-wise inference paths by a policy network. Parameter sharing is adopted such that blocks of the original network can be reused multiple times with no ordering constraint. The policy network learns the optimal strategy via deep reinforcement learning. We expect the new dynamic network to have similar performance as the static one with the same architecture. Experiments are performed with various ResNet models on CIFAR-10 dataset to investigate the effectiveness of the method. |
End-to-End Reinforcement Learning for Autonomous Driving in
CARLA (김찬)

We present research using the reinforcement learning algorithm for end-to-end driving without any hand-crafted perception features such as object detection or scene understanding. Instead the vehicle learns to drive by trial and error, only using RGB image from a forward facing camera. Deep deterministic policy gradient (DDPG) framework is used to learn the car control in CARLA which is open-source simulator for autonomous driving research. The vehicle is trained in town3, which has several road structures such as roundabout, and intersections. The model trained using DDPG is compared with the model trained using Deep QNetwork(DQN) which shows good performance in several reinforcement tasks but can’t deal with the continuous action space. |
Generative Adversarial Imitation Learning with Incomplete expert (황인우)

Generative Adversarial Imitation Learning is a very popular algorithm for imitation reinforcement learning. In the process of learning GAIL, we usually training with complete expert demonstrations. But, In real world, sometimes we could learn more from incomplete expert than complete expert and following the complete expert maybe hard to follow for the beginner. In this respect, i propose a method Generative Adversarial Imitation Learning with Incomplete expert. We could get incomplete expert demonstration set from lower score areas and it is more easy to get complete expert demonstrations. And by multiplying the weights, we could decide how much depend on incomplete expert distribution. The proposed method is evaluated using the MuJoCo simulator and It showed faster convergence and higher performance than original Generative Adversarial Imitation Learning (GAIL). |
Actor-Critic Using the Stochastic Policy in Continuous Action Space for Reinforcement Learning in Video Grounding (김선오)

Video grounding is the area in which a specific segment of a whole video is detected temporally by understanding a sentence that describes the video segment. The existing method uses a reinforcement learning-based method in discrete action spaces, which moves the temporal grounding boundary repeatedly by predefined distances, but, it can not control the temporal boundary delicately to the actual grounding location. To solve this problem, a stochastic policy in the continuous action spaces is exploited in this paper. The stochastic policy is learned by agents based on soft actor-critic, and in the case of short-length video segments, they are found to be more tightly fit to the actual grounding boundary than conventional methods. The proposed method is evaluated on the Tiny Charades-STA data set, which is one-fourth the size of the existing CharadesSTA dataset. It shows comparable results to the reinforcement learning-based method and better performance than supervised learning-based methods and predefined strategies. |
Bimanual manipulation by learning task schema (조대솔)

We address the problem of effectively composing primitives to solve sparse-reward tasks. Given a set of parameterized primitives (such as exerting a force or doing a grasp at a location), our goal is to learn policies that invoke these primitives to efficiently solve such tasks. Our insight is that for many tasks, the learning process can be decomposed into learning a state-independent task schema (a sequence of primitives to execute) and a policy to choose the parameterizations of the primitives in a state-dependent manner. For such tasks, we show that explicitly modeling the schema’s state-independence can yield significant improvements in sample efficiency for model-free reinforcement learning algorithms. Furthermore, these schemas can be extended to transferring to solve related tasks, by simply re-learning the parameterizations with which the primitives are invoked. We validate our approach over robotic bimanual manipulation tasks in simulation |